
TL;DR:
- UC Berkeley unveils Dynalang, an AI agent merging language and visual world models.
- Current embodied agents handle basic commands; Dynalang understands nuanced language contexts.
- Reinforcement learning (RL) trains language-conditioned agents, but struggles with diverse language roles.
- Dynalang asserts language aids future prediction, enhancing comprehension of the world.
- Agents predict changes using prior info; this predictive ability aids in task execution.
- Dynalang separates behavior and world modeling; learns from online experiences.
- Dynalang’s latent world model refines predictions; policy decisions optimize task rewards.
- World modeling and language production can be independent; agents can understand and communicate.
- Dynalang outperforms in multitask settings and complex domains, showcasing versatile language use.
Main AI News:
The pursuit of imbuing AI entities with the ability to seamlessly converse with humans in the tangible realm has always been a cardinal ambition within the realm of artificial intelligence. In the present epoch, embodied agents exhibit a capacity to execute rudimentary directives, such as “retrieve the azure block” or “proceed past the elevator and make a right turn.” However, the evolution of interactive agents mandates a profound comprehension of the diverse linguistic nuances that extend beyond the immediate “here and now.” This encompassing grasp of language encompasses knowledge transfer (“deactivate the television using the top-left button“), contextual intelligence (“we’ve depleted our milk supply“), and collaborative coordination (“I’ve already completed the living room vacuuming“).
The literary and aural narratives that young minds encounter predominantly convey facets of our reality, elucidating its functional mechanics or its present state. Contemplating the question of endowing agents with the gift of multilingual articulation, the discipline of reinforcement learning (RL) has emerged as a pivotal instrument to instill language-conditioned agents with the prowess to surmount challenges. Nevertheless, prevailing language-conditioned RL methodologies predominantly revolve around training agents to enact actions grounded in task-specific directives. This entails transmuting a mission description, like “lift the cobalt-hued block,” into a sequence of mechanical instructions. However, the direct translation of language into optimal action becomes a formidable educational hurdle, considering the myriad roles that natural language assumes in the physical world.
When the exigency lies in tidying up, the agent’s response should seamlessly segue into the subsequent cleaning phase; conversely, when dining arrangements are in order, the agent’s mandate involves gathering the bowls. Take, for instance, the phrase “I stowed away the bowls.” When devoid of task-related context, language exhibits a feeble correlation with the optimal course of action for the agent. Ergo, a mere alignment of language with task-based rewards offers a suboptimal learning signal when it comes to harnessing multifarious linguistic inputs for task fulfillment. Instead, a more unifying function for language in agent cognition emerges – that of fostering future prognostication. The expression “I stowed away the bowls” serves as a conduit for agents to anticipate forthcoming observations with greater precision (e.g., if the cupboard is opened, it will reveal the bowls within).
This lens reveals that a substantial portion of the linguistic exposure young minds undergo stems from visual experiences. Agents are adept at prognosticating shifts in their surroundings by leveraging antecedent data, such as “wrenches are employed to fasten nuts.” Moreover, agents can preemptively conjure observations, foretelling, “the package resides outside.” This paradigm ingeniously amalgamates conventional paradigms of directive adherence under the aegis of predictive paradigms: directives aid agents in the anticipation of forthcoming rewards. This study posits that the predictive potency of future representations endows agents with a robust learning impetus, one that galvanizes them to fathom language and its interplay with the external milieu. Much akin to how the prescience of subsequent tokens empowers language models to sculpt inner schemas of worldly wisdom.
UC Berkeley’s intellectual vanguard introduces Dynalang, a quintessential AI agent poised to imbibe a textual and visual portrayal of the world through dynamic experiential engagement. The Dynalang framework ingeniously bifurcates its learning endeavor into two facets: the mastery of behavioral acumen via the assimilation of the model (executed via reinforcement learning with task-based incentives) and the cognizance of world modeling through linguistic constructs (facilitated by supervised learning employing predictive benchmarks). The model is innervated by inputs of both textual and visual nature, assimilating them within a latent realm of cognition. As the agent interacts with its ecosystem in real-time, these interactions fuel the refinement of the model, facilitating the anticipation of latent manifestations yet to unfurl. With the latent edifice of the world model as its navigational star, the policy iteratively refines its decisions, all while endeavoring to maximize task-derived rewards.
Uniquely, the realm of world modeling stands demarcated from the domain of action, granting Dynalang the prerogative of being pre-trained on individual modalities, whether it’s solely textual or visual data, devoid of explicit tasks or rewards. Moreover, the edifice for language synthesis is seamlessly harmonized: the agent’s perceptual acumen assumes a role in shaping its linguistic model (manifested through predictions regarding impending tokens), thereby facilitating a discourse pertaining to the environment, unveiled through linguistic articulations within the action continuum.
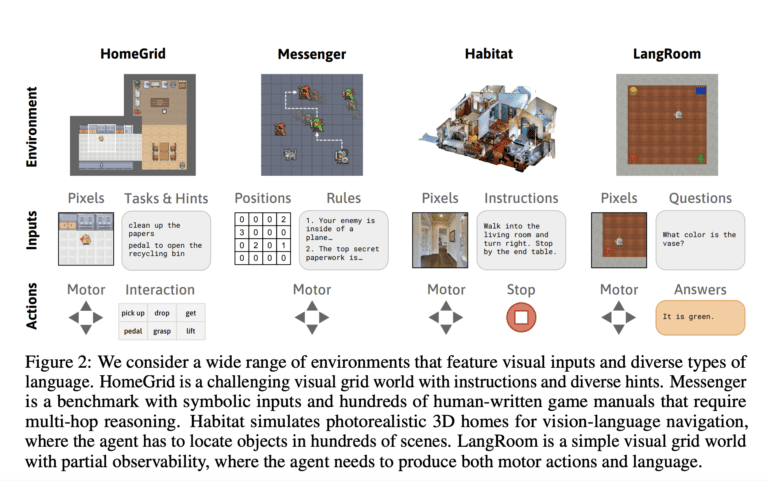
The experimental validation of Dynalang spans a gamut of domains, each characterized by intricate linguistic contexts. Dynalang astutely discerns linguistic cues concerning prospective observations, environmental dynamics, and corrective maneuvers, translating this sagacity into expedited task completion within the ambit of household chores. In a challenging arena such as the Messenger benchmark, Dynalang surges ahead, eclipsing task-specific architectural paradigms, achieved through a comprehensive assimilation of game manuals to conquer the most formidable stages. This substantiates Dynalang’s adeptness in interpreting complex instructions embedded within both visual and linguistic terrains, specifically illustrated in the milieu of vision-language navigation.
Conclusion:
The introduction of Dynalang marks a pivotal advancement in AI’s interaction with the real world. Its ability to comprehend and utilize language beyond basic instructions opens doors for enhanced human-AI communication. Dynalang’s predictive prowess and multifaceted linguistic understanding present significant market potential. Industries ranging from customer service to home automation could benefit as Dynalang’s capabilities reshape AI-driven interactions, enabling more intuitive and efficient engagement.