
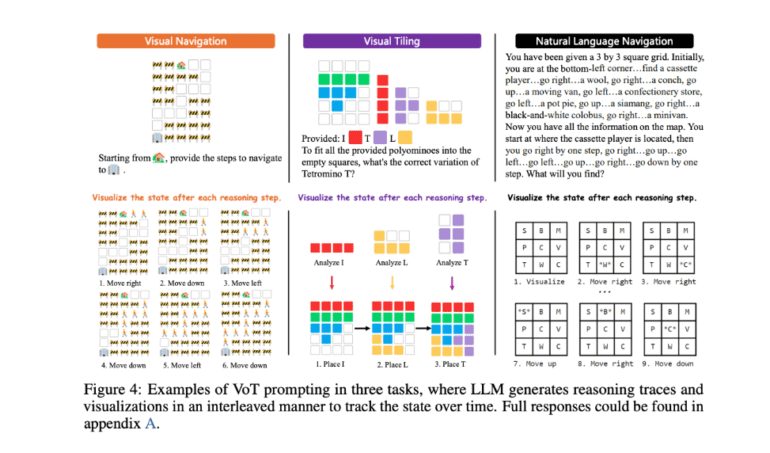
- Microsoft researchers propose Visualization-of-Thought (VoT) prompting to enhance spatial reasoning in large language models (LLMs).
- VoT enables LLMs to generate and manipulate mental images akin to human cognitive processes.
- GPT-4 VoT demonstrates superior performance across various tasks compared to other settings, indicating its effectiveness in spatial reasoning.
- The research introduces novel tasks and synthetic datasets, providing a robust testbed for spatial reasoning research.
- VoT holds promise for narrowing the gap between machine intelligence and human cognition.
Main AI News:
In the realm of large language models (LLMs), a critical deficiency has been uncovered: their limited capacity for spatial reasoning, a fundamental aspect of human cognitive prowess. While these models demonstrate impressive linguistic capabilities, they fall short in simulating the spatial imagination akin to human cognition, a deficiency that has been largely overlooked until now.
Recent studies underscore the formidable linguistic prowess of LLMs while shedding light on their underexplored spatial reasoning abilities. In contrast to humans, whose cognition seamlessly integrates verbal and spatial reasoning, LLMs predominantly rely on verbal processing. Yet, it is through spatial imagination—manifested in mental imagery—that humans navigate their environment and engage in complex cognitive tasks.
Enter Visualization-of-Thought (VoT) prompting, a groundbreaking approach proposed by Microsoft researchers to bridge this gap. VoT introduces a novel method for generating and manipulating mental images within LLMs, akin to the human mind’s eye, thereby facilitating spatial reasoning. By leveraging a visuospatial sketchpad, VoT enables LLMs to visualize logical steps, thereby augmenting their spatial reasoning capabilities.
Crucially, VoT operates on zero-shot prompting, harnessing the innate ability of LLMs to glean mental imagery from text-based visual stimuli. This innovative approach diverges from conventional methods reliant on pre-trained demonstrations or text-to-image techniques, offering a more flexible and scalable solution.
The performance of GPT-4 VoT speaks volumes about its efficacy in bolstering spatial reasoning within LLMs. Comparative analyses across various tasks and metrics consistently demonstrate its superiority over alternative settings. For instance, in the realm of natural language navigation, GPT-4 VoT outshines its counterpart, which lacks VoT functionality by a notable margin of 27%. Furthermore, comparisons with GPT-4 CoT underscore the significance of grounding LLMs in a 2D grid for optimal spatial reasoning.
The significance of this research extends beyond mere technological advancement; it introduces a paradigm shift in understanding and enhancing spatial reasoning within LLMs. By dissecting the nature of mental imagery and its origins in code pre-training, this study lays a robust foundation for future investigations. Moreover, the introduction of novel tasks such as “visual navigation” and “visual tiling,” accompanied by synthetic datasets, offers a rich and diverse landscape for testing spatial reasoning capabilities.
Conclusion:
The introduction of Visualization-of-Thought (VoT) prompting by Microsoft researchers represents a significant advancement in the field of large language models. By enhancing spatial reasoning capabilities, VoT opens doors for applications across diverse sectors, including artificial intelligence, cognitive science, and beyond. This innovation underscores the potential for LLMs to approach human-like cognitive abilities, heralding a new era of innovation and exploration in the market.