
TL;DR:
- Microsoft Research introduces phi-1, a specialized language model focused on Python coding with a significantly smaller size compared to competing models.
- The study investigates the impact of high-quality data on enhancing the performance of large language models (LLMs) while reducing dataset size and training computation.
- Phi-1, trained on a 1.3B-parameter model, defies established scaling rules by achieving impressive accuracy scores on code-related tasks.
- The model utilizes “textbook quality” data, including synthetic generation and web-sourced filtering, followed by fine-tuning on “textbook-exercise-like” data.
- Despite its smaller size, phi-1 outperforms larger competitors and demonstrates the potential of high-quality data in optimizing LLM performance.
Main AI News:
In the realm of developing massive artificial neural networks, the advent of the Transformer design revolutionized the field, yet our understanding of the science behind this breakthrough is still in its nascent stages. Amidst the plethora of perplexing results that surfaced around the time Transformers made their debut, a semblance of order began to emerge. It became evident that performance gains could be reliably achieved by increasing either computational resources or network size—a phenomenon is now known as scaling laws. These guiding principles paved the way for further investigations into the scalability of deep learning models, leading to the discovery of variations in these laws that yielded significant performance improvements.
This paper delves into an alternative dimension of enhancing data quality. The authors explore how improving the quality of data can yield superior outcomes. Notably, data cleaning, a critical step in generating contemporary datasets, can lead to more streamlined datasets and the ability to iterate data more extensively. Recent research on TinyStories, an artificially constructed high-quality dataset for teaching neural networks English, demonstrated the far-reaching advantages of superior data quality. By introducing profound changes to the scaling laws, enhanced data quality has the potential to match the performance of large-scale models while demanding significantly fewer resources for training and modeling.
In this study, Microsoft Research presents compelling evidence showcasing the augmentative power of good-quality data in the realm of large language models (LLMs). By leveraging LLMs trained specifically for coding, the authors construct tailored Python functions from docstrings. The evaluation benchmark employed, known as HumanEval, has proven invaluable in comparing LLM performance for code-related tasks.
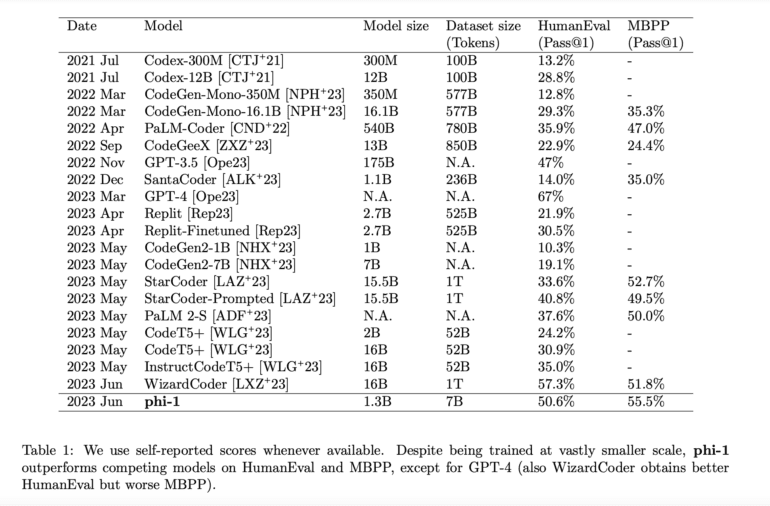
The authors astoundingly defy established scaling rules by training a 1.3B-parameter model, aptly named phi-1. The training process entails approximately eight passes over 7B tokens, amounting to slightly over 50B total tokens observed, followed by fine-tuning on a modest dataset of less than 200M tokens. Broadly speaking, the pretraining stage involves leveraging “textbook quality” data, which comprises both synthetically generated data using GPT-3.5 and filtered content from web sources. Subsequently, the model is fine-tuned using “textbook-exercise-like” data. Despite being orders of magnitude smaller than competing models, both in terms of dataset size and model size (refer to Table 1), phi-1 achieves remarkable accuracy scores of 50.6% pass@1 on HumanEval and 55.5% pass@1 on MBPP (Mostly Basic Python Programs). These figures represent some of the most impressive self-reported results utilizing a single LLM generation.
By training the phi-1 model with 1.3B parameters over the course of approximately eight runs on 7B tokens, with a cumulative observation of just over 50B tokens, followed by fine-tuning on fewer than 200M tokens, the authors compellingly illustrate the capacity of high-quality data to challenge established scaling rules. Their pretraining strategy, involving meticulously curated “textbook quality” data, whether artificially generated through GPT-3.5 or filtered from online sources, combined with fine-tuning on “textbook-exercise-like” data, produces outstanding performance metrics. Despite its diminutive size compared to competing models, phi-1 achieves an impressive 50.6% pass@1 accuracy on HumanEval and 55.5% pass@1 accuracy on MBPP (Mostly Basic Python Programs), firmly establishing its position as one of the top-performing single LLM architectures.
Conclusion:
The introduction of phi-1 by Microsoft Research represents a significant advancement in the field of language models, particularly for Python coding. This compact model challenges established scaling rules by showcasing superior performance while requiring fewer computational resources and smaller datasets. Its ability to leverage high-quality data to achieve impressive accuracy scores on code-related tasks suggests a promising future for more efficient and effective language models. This development has the potential to reshape the market by providing developers and organizations with a powerful, streamlined tool for coding tasks, reducing environmental costs and enhancing productivity.