
TL;DR:
- LMFlow is an efficient toolkit for the personalized fine-tuning of large language models (LLMs).
- It addresses the need for further optimization and performance enhancement in specialized domains or specific tasks.
- The toolkit offers a unified approach to fine-tuning across various prebuilt models like GPT-J, Bloom, and LLaMA.
- With just a single Nvidia 3090 GPU and five hours, users can train custom models based on the 7-billion-parameter LLaMA model.
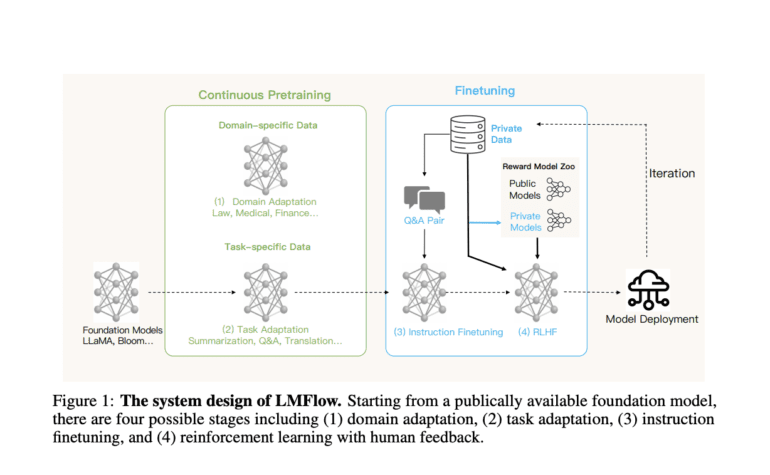
- LMFlow provides a four-step process: domain adaptation, task adaptation, instruction finetuning, and reinforcement learning with human feedback.
- The toolkit facilitates individualized training of LLMs, even with limited computational resources.
- Users can choose suitable models for activities like question answering, writing, translation, and expert consultations based on available resources.
- LMFlow’s continuous pretraining, instruction tuning and reinforcement learning features make personalized model training accessible to all.
- Superior outcomes can be achieved by extending the training duration, as demonstrated by the team’s 33-billion-parameter model that outperforms ChatGPT.
Main AI News:
In the realm of artificial intelligence, the emergence of large language models (LLMs) built upon expansive foundation models has unlocked unprecedented capabilities for tackling diverse tasks. However, to achieve optimal performance in specialized domains or specific jobs, further fine-tuning of these LLMs becomes essential. Traditionally, several methods have been employed to refine these colossal models, including ongoing pretraining in niche areas, instructive tuning, and reinforcement learning. While various prebuilt models like GPT-J, Bloom, and LLaMA have been made available to the public, a unified toolkit capable of efficiently facilitating fine-tuning across these models has been noticeably absent.
To address this critical gap and empower developers and researchers to effectively fine-tune and harness the potential of massive models even with limited resources, a collaborative effort between Hong Kong University and Princeton University has given birth to an accessible and lightweight toolset—LMFlow.
By leveraging the power of a single Nvidia 3090 GPU and dedicating just five hours, one can now train a customized model based on the 7-billion-parameter LLaMA model. Furthermore, the research team has generously shared the model weights for academic exploration, having utilized this framework to fine-tune LLaMA variants ranging from 7 billion to a staggering 65 billion parameters on a single machine.
Optimizing the output of publicly available large language models can be achieved through four fundamental steps, each meticulously executed within LMFlow:
- Domain Adaptation: The initial stage involves training the model within a specific domain to enhance its performance and comprehension.
- Task Adaptation: Here, the focus shifts towards training the model to excel in accomplishing specific objectives, such as summarization, question answering, or translation.
- Instruction Finetuning: This stage revolves around refining the model’s parameters through instructional question-answer pairings, further honing its capabilities.
- Reinforcement Learning with Human Feedback: The final step entails enhancing the model’s performance by incorporating valuable feedback from human users, iteratively improving its effectiveness.
LMFlow provides a comprehensive and streamlined finetuning process, enabling individualized training of massive language models, even in the face of computational constraints. With features such as continuous pretraining, instruction tuning, and reinforcement learning with human feedback, LMFlow empowers users with easy-to-use and flexible APIs, making personalized model training accessible to all.
Whether it’s question answering, companionship, writing, translation, or seeking expert consultations across a plethora of subjects, LMFlow offers users the ability to select a suitable model based on their available resources. Notably, users with substantial models and datasets can achieve superior outcomes by extending the training duration. In fact, the research team recently trained a 33-billion-parameter model that surpasses the performance of ChatGPT, marking a significant milestone in the field.
Conclusion:
The emergence of LMFlow as an efficient toolkit for personalized fine-tuning of large language models holds significant implications for the market. It enables developers and researchers to unlock the full potential of LLMs in specialized domains and specific tasks, delivering superior AI performance. By democratizing the process of model customization and training, LMFlow empowers businesses to leverage AI capabilities tailored to their unique requirements, even with limited computational resources. This advancement opens doors to a new era of personalized AI experiences, driving innovation and fostering the adoption of AI technologies across diverse industries. As organizations harness the power of LMFlow, we can expect accelerated advancements in natural language processing, question answering, translation, and more, leading to enhanced productivity, improved customer experiences, and a competitive edge in the market.