
TL;DR:
- MosaicML introduces the MPT-30B, a revolutionary pretrained transformer surpassing ChatGPT3.
- MosaicML-7B’s success prompted the development of MPT-30B, catering to diverse use cases.
- MPT-30B offers lightweight and powerful models for commercial usage.
- Features like LLaVA-MPT and GGML enhance MosaicML’s models for vision and optimized performance.
- Competitive advantages lie in adaptability, easy integration, and superior features.
- MPT-30B outperforms ChatGPT3 with one-third of the parameters, making it highly efficient.
- MPT-30B-Instruct and MPT-30B-Chat excel at single instruction and multiturn conversation tasks.
- MPT-30B is designed bottom-up, ensuring every component performs efficiently.
- FlashAttention and diverse data contribute to enhanced training and inference capabilities.
- MPT-30B’s lightweight nature and accessibility make it cost-effective for emerging organizations.
Main AI News:
In a stunning display of innovation, MosaicML has once again raised the bar with its latest release, the MosaicML-30B. Following the remarkable success of the MosaicML-7B, the company has outdone itself by introducing this groundbreaking model, which has set a new standard in the field of artificial intelligence.
Renowned for its precision and power, MosaicML has boldly claimed that the MosaicML-30B surpasses even the highly acclaimed ChatGPT3. With its remarkable performance and cutting-edge capabilities, this new release has garnered significant attention within the AI community.
The impact of MosaicML’s previous model, the MosaicML-7B, cannot be overstated. Its base-instruct, base-chat, and story writing features achieved unprecedented success, with downloads surpassing the 3 million mark worldwide. Inspired by the overwhelming response from the community, MosaicML embarked on the journey to create an even more exceptional engine – and they have accomplished just that with the MPT-30B.
The MPT-30B has proven to be a catalyst for pushing the boundaries of AI technology. It has spurred the development of remarkable use cases, such as LLaVA-MPT, which enhances pretrained MPT-7B models with vision understanding. Additionally, GGML has optimized MPT engines to deliver superior performance on Apple Silicon and CPUs. Another noteworthy use case is GPT4ALL, which leverages MPT as its base engine to provide a GPT4-like chat option.
A closer examination reveals the key factors that set MosaicML apart, allowing them to rival and surpass larger firms in the industry. The competitive edge lies in the array of features they offer and the remarkable adaptability of their models to diverse use cases, seamlessly integrating with existing systems.
MosaicML proudly asserts that their MPT-30B outshines the current ChatGPT3 while utilizing just one-third of the parameters, resulting in an exceptionally lightweight model compared to other generative solutions. Notably, this superior offering surpasses the performance of their own MPT-7B. Moreover, the MPT-30B is available for commercial use under a convenient commercial license.
But that’s not all – the MPT-30B comes with two pretrained models: MPT-30B-Instruct and MPT-30B-Chat. These models exhibit the extraordinary ability to be influenced by a single instruction and adeptly handle multiturn conversations over extended periods of time.
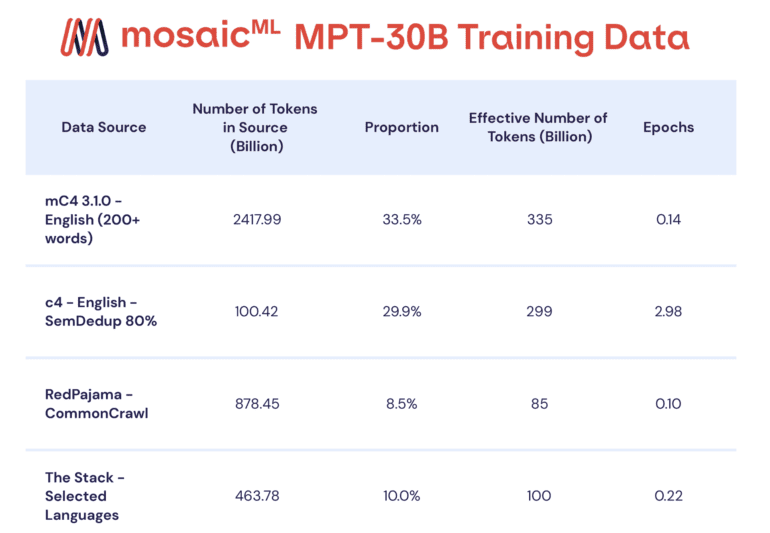
The excellence of the MPT-30B extends beyond its core capabilities. MosaicML’s bottom-up approach to design has resulted in a more robust and efficient model. Trained with an 8k token context window, the MPT-30B supports longer contexts through ALiBi. Additionally, the implementation of FlashAttention has significantly improved training and inference performance. The MPT-30B also showcases enhanced coding abilities, a direct outcome of the diverse range of data utilized during its development. Notably, this model has been extended to an 8K context window on Nvidia’s H100, making it the first LLM model trained on this platform, which is readily accessible to customers.
MosaicML has also prioritized keeping the MPT-30B lightweight, ensuring that emerging organizations can minimize operational costs. The model’s size has been specifically chosen to facilitate easy deployment on a single GPU. With just 1xA100-80GB in 16-bit precision or 1xA100-40GB in 8-bit precision, the system can seamlessly run. In contrast, other comparable LLMs, such as Falcon-40B, require multiple GPUs and are unable to operate on a single data center GPU. This key advantage translates into lower minimum inference system costs, making the MPT-30B an optimal choice for organizations of all sizes.
Conclusion:
The release of MosaicML’s MPT-30B signifies a significant breakthrough in pretrained transformers. With its superior performance, adaptability, and efficiency, MPT-30B presents a formidable alternative to established players in the market. Its lightweight design, coupled with the provision of powerful pretrained models, offers emerging organizations an opportunity to leverage cutting-edge AI technology while keeping operational costs low. MosaicML’s innovative approach and commitment to pushing the boundaries of AI showcase their potential to reshape the market and drive advancements in the field of artificial intelligence.