
TL;DR:
- Multimodal Large Language Models (MLLMs) have advanced, but struggle with precise location dialogue.
- Shikra, a Chinese MLLM, enables referential dialogue (RD) by handling spatial coordinates.
- Shikra provides natural language numerical forms for input and output coordinates.
- The model incorporates an alignment layer, an LLM, and a vision encoder for simplicity.
- Shikra excels in tasks like Visual Question Answering (VQA) and Referring Expression Comprehension (REC).
- The research stimulates future MLLM advancements with analytical experiments.
Main AI News:
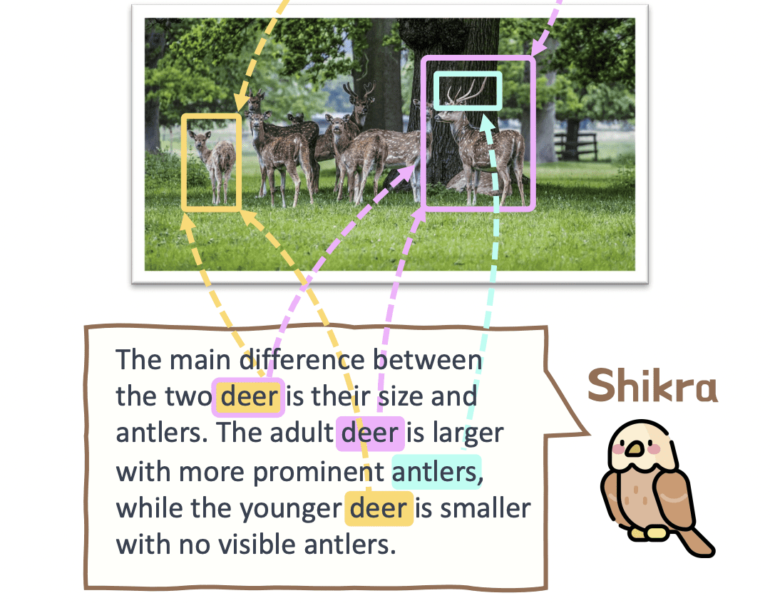
Multimodal Large Language Models (MLLMs) have made significant strides in recent months, capturing widespread attention. These models have primarily focused on understanding visual content through Large Language Models (LLMs), enabling discussions about input images. However, a critical limitation of these models is their inability to engage in conversations about precise locations within the images. Both users and models struggle to pinpoint specific positions of objects or regions in a picture. Contrastingly, in everyday human conversations, people effortlessly refer to distinct areas or items within a scene, effectively sharing information. Termed referential dialogue (RD), this form of communication holds immense potential for various applications. Imagine an AI assistant, like Shikra, where users can indicate anything while wearing Mixed Reality (XR) headsets such as the Apple Vision Pro. Shikra would instantly display the corresponding area within the user’s field of vision, allowing seamless interaction. Furthermore, Shikra empowers visual robots to understand users’ unique reference points, facilitating improved human-robot collaboration. In the realm of online shopping, assisting consumers in exploring objects of interest within images can enhance their purchasing experience. This study introduces Shikra, an MLLM designed to unlock the power of referential conversation.
Collaboratively developed by researchers from SenseTime Research, SKLSDE, Beihang University, and Shanghai Jiao Tong University, Shikra represents a groundbreaking unified model capable of handling spatial coordinates as both input and output. Notably, Shikra achieves this feat without requiring additional vocabularies or position encoders, as all coordinates are provided in natural language numerical form. The architectural components of Shikra comprise an alignment layer, an LLM, and a vision encoder, meticulously crafted to ensure simplicity and cohesiveness. Eschewing the need for pre-/post-detection modules or plug-in models, Shikra offers an intuitive and streamlined approach. The researchers provide users with numerous interaction possibilities on their website, enabling comparisons between different areas, inquiries about thumbnail meanings, and discussions about specific objects, among other functionalities. Crucially, Shikra possesses the ability to answer questions, both verbally and spatially, providing justifications for its responses.
The role of referential discourse in vision-language (VL) extends beyond mere task completion. Shikra, proficient in RD, effortlessly handles tasks like Visual Question Answering (VQA), picture captioning, Referring Expression Comprehension (REC), and pointing, all with promising outcomes. Additionally, this essay delves into intriguing inquiries, such as how to accurately depict location within an image. Can MLLMs from the past comprehend absolute positions? Can leveraging geographical information enhance reasoning and yield more precise answers? By conducting analytical experiments, the authors aim to stimulate future research on MLLMs.
The essay’s key contributions are as follows:
- Introduction of Referential Dialogue (RD) as an essential aspect of human communication with numerous practical applications.
- Shikra, a versatile MLLM, serves as an RD specialist. Shikra’s elegance lies in its unified design that eliminates the need for additional vocabularies, pre-/post-detection modules, or plug-in models.
- Shikra adeptly handles hidden configurations, enabling diverse application scenarios. Impressively, it delivers strong performance on common visual language tasks like REC, PointQA, VQA, and image captioning, even without fine-tuning. The code for Shikra is publicly available on GitHub.
As Shikra ushers in a new era of spatial dialogue, this research paves the way for further advancements in the realm of MLLMs. The possibilities for seamless human-AI interaction and enhanced understanding of visual content are within reach, empowering us to explore new frontiers in artificial intelligence.
Conclusion:
The introduction of Shikra, a groundbreaking multimodal LLM by Chinese researchers, has significant implications for the market. Shikra addresses a critical limitation of existing models by enabling referential dialogue with precise spatial coordinates. This opens up new possibilities for seamless human-AI interaction, enhanced understanding of visual content, and improved applications in fields such as mixed reality, robotics, and online shopping. As Shikra’s capabilities gain recognition, businesses involved in AI, natural language processing, and computer vision should closely monitor its developments to leverage its potential for their own products and services.