
TL;DR:
- Generating 3D objects from a single image is a challenge for computer vision models.
- Existing methods have limitations in reconstructing fine geometry and rendering large views.
- Make-it-3D leverages implicit 3D knowledge in a 2D diffusion model.
- The two-stage approach improves the fidelity of 3D models to reference images.
- Texture enhancement is a key focus to achieve high-quality rendering.
- Make-it-3D opens new possibilities for creating high-fidelity 3D content.
Main AI News:
In the realm of human imagination, lies the ability to envision objects from different perspectives based on a single image. However, this feat remains a daunting challenge for computer vision and deep learning models. The generation of three-dimensional (3D) objects from a lone viewpoint is complex due to the limited information available. While several approaches, such as 3D photo effects and single-view 3D reconstruction, have been proposed, they often struggle with reconstructing intricate geometry and rendering expansive views. Additionally, existing techniques are confined to specific object classes, lacking the capability to handle general 3D objects. Overcoming these limitations is an uphill battle, impeding the development of diverse datasets and powerful 3D foundation models for estimating novel views and general objects.
Despite the abundance of images, 3D models remain scarce. Recent advancements in diffusion models, including Midjourney and Stable Diffusion, have witnessed significant strides in 2D image synthesis. Notably, well-trained image diffusion models have demonstrated the ability to generate images from different viewpoints, hinting at their implicit assimilation of 3D knowledge.
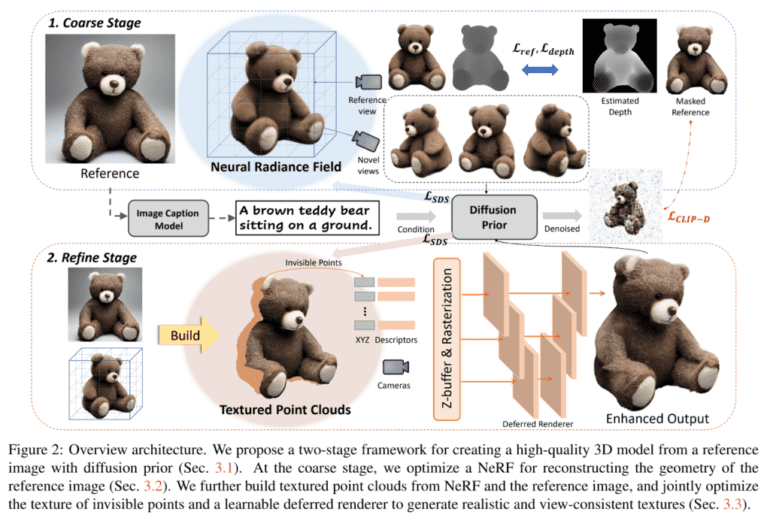
Building upon this observation, this article explores the groundbreaking potential of leveraging implicit 3D knowledge within a 2D diffusion model to reconstruct 3D objects. Introducing Make-it-3D, a two-stage approach designed to generate high-fidelity 3D content from a single image by harnessing the power of diffusion priors.
In the first stage, the diffusion prior plays a pivotal role in enhancing the neural radiance field (NeRF) through score distillation sampling (SDS). Furthermore, reference-view supervision serves as a valuable constraint for optimization. Diverging from previous text-to-3D methodologies that emphasize textual descriptions, Make-it-3D prioritizes the faithfulness of the 3D model to the reference image, given its focus on image-based 3D creation. However, despite the alignment of SDS-generated 3D models with textual descriptions, they often fail to faithfully align with reference images, which fail to capture all the intricate object details. Addressing this challenge, the model strives to maximize the similarity between the reference image and the new view, rendered with reduced noise through a diffusion model. Leveraging the abundance of geometry-related information inherently present in images, the depth of the reference image serves as an additional geometry prior, alleviating the ambiguity in NeRF optimization pertaining to shape.
The initial stage of the 3D model generation process yields a rudimentary model with reasonable geometry. However, its appearance often falls short of matching the quality of the reference image, characterized by oversmooth textures and saturated colors. Therefore, it becomes imperative to enhance the model’s realism by bridging the gap between the rough model and the reference image. Recognizing that texture plays a pivotal role in high-quality rendering, the second stage of Make-it-3D concentrates on texture enhancement while preserving the geometry established in the initial stage. The final refinement entails leveraging ground-truth textures for regions visible in the reference image, achieved by mapping NeRF models and textures to point clouds and voxels.
Conclusion:
Make-it-3D represents a significant breakthrough in the field of 3D object generation. By leveraging implicit 3D knowledge within a 2D diffusion model, this approach addresses the limitations of existing methods and enables the creation of high-fidelity 3D content from a single image. With its ability to reconstruct fine geometry, render large views, and prioritize texture enhancement, Make-it-3D opens up new horizons for industries such as gaming, virtual reality, and product visualization. This technology has the potential to revolutionize the market by providing more accessible and efficient ways to generate realistic 3D objects, unlocking new possibilities for designers, developers, and content creators.