
TL;DR:
- Display technology advancements have intensified our viewing experience, but high-quality content is often inaccessible due to data costs.
- Super-resolution and video interpolation methods enhance video resolution and frame count, respectively.
- Video frame interpolation involves inserting new frames by estimating motion between existing frames.
- Evaluating the quality of interpolation results has been challenging, as existing metrics may not align with human perception.
- Researchers propose a novel neural network architecture based on Swin Transformers for perceptual quality assessment.
- The network predicts the perceptual similarity score between original and interpolated frames.
- A specialized dataset, combined with L1 and SSIM objective metrics, is used to train the network.
- The proposed method does not rely on reference frames, making it suitable for client devices.
Main AI News:
The rapid evolution of display technology has revolutionized our viewing encounters, elevating them to new heights of intensity and satisfaction. The sheer delight of watching content in glorious 4K resolution at 60 frames per second (FPS) far surpasses the experience of a standard 1080P video running at 30 FPS. The former engulfs viewers in its captivating allure, making them feel like active participants in the on-screen action. Alas, not everyone can revel in this visual extravaganza, as such high-quality content comes at a price. Producing a single minute of 4K 60FPS video demands approximately six times more data than its 1080P 30FPS counterpart, rendering it inaccessible to a significant number of users.
Fortunately, a viable solution exists to address this dilemma: augmenting the resolution and/or framerate of delivered videos. Super-resolution techniques primarily focus on enhancing the resolution, while video interpolation methods specialize in increasing the number of frames within a video. Video frame interpolation involves the insertion of new frames into a video sequence by accurately estimating the motion between existing frames. This sophisticated technique has found applications in diverse domains, including slow-motion videos, frame rate conversion, and video compression. The resulting output delights viewers with its seamless flow and enhanced visual appeal.
In recent years, researchers have made substantial strides in the realm of video frame interpolation, achieving remarkable results. These advancements enable the generation of intermediate frames with exceptional accuracy, significantly enhancing the viewing experience. However, evaluating the quality of interpolation outcomes has long posed a formidable challenge. Existing evaluation metrics often rely on off-the-shelf algorithms, which occasionally fail to align with human perception when assessing the interpolation results. Although some methods resort to subjective tests for more accurate measurements, such endeavors prove time-consuming, barring a few exceptional cases that leverage user studies. Hence, a pressing question emerges: How can we accurately assess the quality of our video interpolation techniques? The time for answers has come.
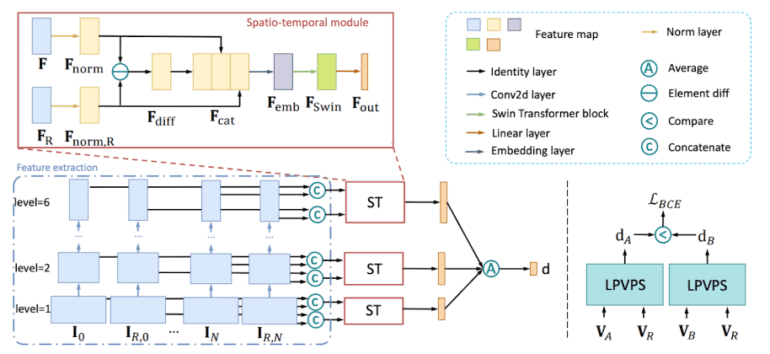
A team of enterprising researchers has introduced a specialized perceptual quality metric tailored for evaluating video frame interpolation results. Leveraging the power of Swin Transformers, they designed a groundbreaking neural network architecture dedicated to video perceptual quality assessment. This innovative network accepts a pair of frames as input—one from the original video sequence and the other an interpolated frame—and produces a score indicative of the perceptual similarity between the two frames. The researchers embarked on their journey by assembling an extensive dataset specifically curated for video frame interpolation perceptual similarity. This meticulously crafted dataset comprises pairs of frames sourced from diverse videos, accompanied by human judgments regarding their perceptual similarity. To train the network effectively, a combination of L1 and SSIM objective metrics was employed.
The L1 loss, measuring the absolute difference between the predicted score and the ground truth score, and the SSIM loss, quantifying the structural similarity between two images, synergistically guide the network towards generating scores that align with human perception while maintaining accuracy. A key advantage of this pioneering method lies in its independence from reference frames, enabling its deployment on client devices that lack access to such supplementary information.
Conclusion:
The introduction of a dedicated perceptual quality metric for video frame interpolation signifies a significant breakthrough in the market. By accurately assessing the visual fidelity of interpolated frames, this method empowers businesses to deliver more captivating and immersive video experiences to their users. The ability to leverage advanced neural network architectures and perceptual assessment techniques opens up new avenues for enhancing the quality of video content, enabling companies to differentiate themselves and cater to the growing demand for high-quality visual experiences. This advancement holds the potential to drive market growth and further innovation in the field of video technology.