
TL;DR:
- ReLoRA: A groundbreaking AI method proposed by the University of Massachusetts Lowell.
- Uses low-rank updates to train high-rank networks with significantly reduced computational costs.
- Challenges the need for overparametrization in training models.
- Achieves results comparable to standard neural network training.
- Incorporates innovative techniques like warm start, merge-and-rein-it, and a jagged learning rate scheduler.
- Effective for training large networks with billions of parameters.
- Offers promise for boosting training efficiency and advancing deep learning theories.
Main AI News:
In the ever-evolving field of machine learning, training larger and more over parametrized networks has become the new standard. Researchers from the esteemed University of Massachusetts Lowell have recently introduced ReLoRA, a cutting-edge AI method that utilizes low-rank updates to achieve high-rank training. This groundbreaking approach tackles the challenges associated with training models that possess orders of magnitude more parameters than the training instances themselves.
Traditionally, the prevailing strategy has been to stack more layers in the network, resulting in an exponential increase in computing expenses. However, this approach has proven to be financially burdensome for most research groups, thereby necessitating a more cost-effective solution. While alternative approaches such as compute-efficient scaling optima, retrieval-augmented models, and extended training of smaller models have shown promise, they fail to democratize the training process or provide a comprehensive understanding of the need for over-parametrized models.
Recent empirical evidence supports the Lottery Ticket Hypothesis, which asserts that certain sub-networks within a larger network, known as “winning tickets,” exhibit exceptional performance when trained independently. This finding indicates that overparametrization is not a prerequisite for training successful models.
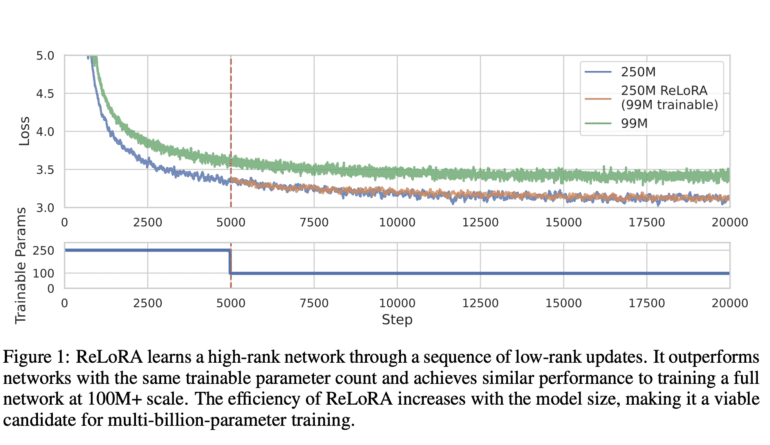
Addressing this issue, the University of Massachusetts Lowell researchers devised ReLoRA, a revolutionary technique that leverages the rank of sum property to train high-rank networks using a series of low-rank updates. Remarkably, their findings demonstrate that ReLoRA achieves results comparable to standard neural network training while significantly reducing computational costs.
ReLoRA employs a full-rank training warm start, inspired by the lottery ticket hypothesis with rewinding. By incorporating a merge-and-rein-it (restart) approach, a jagged learning rate scheduler, and partial optimizer resets, ReLoRA further enhances its efficiency. These advancements bring ReLoRA closer to full-rank training, particularly in the context of large networks, where its impact is most profound.
To evaluate ReLoRA’s performance, the researchers conducted tests using 350 million-parameter transformer language models. They focused specifically on autoregressive language modeling, a task that holds widespread relevance across various neural network applications. Encouragingly, the results showcased ReLoRA’s increasing effectiveness with larger model sizes, suggesting its potential suitability for training networks with billions of parameters.
The researchers firmly believe that developing low-rank training approaches holds immense promise for enhancing the efficiency of training large language models and neural networks. They anticipate that insights gained from low-rank training can deepen our understanding of gradient descent and the impressive generalization abilities of over-parametrized neural networks. By shedding light on these aspects, ReLoRA has the potential to significantly contribute to the advancement of deep learning theories.
Conclusion:
The introduction of ReLoRA by the University of Massachusetts Lowell represents a significant breakthrough in the realm of high-rank training for AI models. By leveraging low-rank updates, ReLoRA provides a cost-effective solution to the challenges associated with training models with a vast number of parameters. This has implications for the market as it offers a more efficient approach to training large language models and neural networks, reducing computational expenses and enabling scalability. The potential of ReLoRA to bridge the gap between low-rank and full-rank training opens up new possibilities for the development of highly efficient and powerful AI models, unlocking their full potential and driving advancements in the field of machine learning.