
TL;DR:
- Retentive Networks (RetNet) introduces a revolutionary architecture for large language models.
- It achieves training parallelism, low-cost inference, and competitive performance, overcoming the limitations of traditional Transformers.
- The multi-scale retention mechanism and recurrent representations optimize GPU utilization and memory efficiency.
- RetNet excels in long-sequence modeling by cleverly encoding global and local blocks iteratively.
- Extensive trials demonstrate RetNet’s impressive scaling curves and in-context learning capabilities.
- It outperforms Transformers in decoding speed, memory usage, and training acceleration.
- RetNet’s inference latency remains unaffected by batch size variations, offering exceptionally high throughput.
Main AI News:
In the fast-paced world of language modeling, innovation is the key to success. Over the years, Transformer architecture has emerged as the go-to solution for building large language models. However, it comes with its own set of limitations, hindering deployment and impacting inference performance. Today, we present to you a game-changer in the field of language models – Retentive Networks (RetNet).
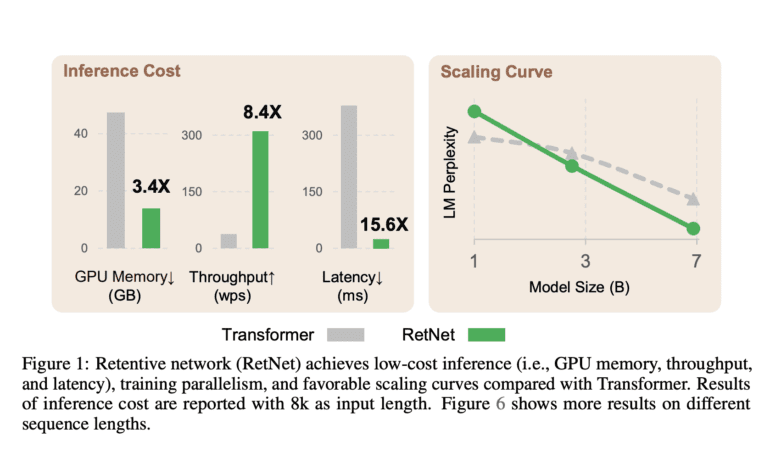
Addressing the shortcomings of traditional Transformers, RetNet pioneers a unique approach that achieves training parallelism, low-cost inference, and exceptional performance. The “impossible triangle” challenge, depicted in Figure 1, has long plagued researchers striving to find an optimal solution. Nonetheless, the collaboration between Microsoft Research and Tsinghua University has culminated in the birth of RetNet.
So, what makes RetNet stand out? Let’s delve into its groundbreaking features.
Training Parallelism and Efficient Inference: RetNet introduces a multi-scale retention mechanism, leveraging three processing paradigms – similar, recurrent, and chunkwise recurrent representations. By replacing the conventional multi-head attention, RetNet unlocks the true potential of GPU devices, fully utilizing their capabilities for parallel model training. This remarkable feat is achieved through efficient parallel representation and recurrent inference, leading to an O(1) complexity in terms of memory and computation. The deployment cost and latency are significantly reduced, thanks to this novel approach.
Effective Long-Sequence Modeling: With the chunkwise recurrent representation, RetNet achieves effective long-sequence modeling. By encoding global blocks iteratively, RetNet conserves valuable GPU memory, while simultaneously encoding each local block to expedite processing. This ingenious technique results in remarkable performance gains.
Unmatched Performance: Extensive trials comparing RetNet with Transformers and its derivatives have validated its prowess. In language modeling experiments, RetNet consistently competes favorably, showcasing impressive scaling curves and in-context learning capabilities. Furthermore, RetNet’s inference cost remains invariant across different sequence lengths, proving its versatility.
Impressive Metrics: RetNet has proven its mettle in quantitative metrics. It boasts a staggering 8.4x faster decoding speed and utilizes a remarkable 70% less memory than Transformers equipped with key-value caches, even with a 7B model and an 8k sequence length. Not stopping there, RetNet also outperforms highly optimized FlashAttention, while saving 25-50% more memory during training acceleration. Its inference latency remains unaffected by batch size variations, delivering an unmatched throughput.
Embracing the Future: With its fascinating features, RetNet emerges as a formidable replacement for big language models. Its efficiency, scalability, and remarkable performance make it a clear choice for businesses seeking state-of-the-art language models.
Conclusion:
Retentive Networks (RetNet) brings a paradigm shift to the language modeling market. With its innovative architecture, it addresses crucial challenges faced by traditional Transformers, offering unparalleled performance and efficiency. Businesses looking to stay ahead in the competitive landscape should consider adopting RetNet as their language model solution to reap the benefits of its superior capabilities.