
TL;DR:
- Diffusion models surpass BigBiGAN in both image creation and image categorization tasks.
- Unified self-supervised representation learning remains an area of exploration.
- Generative and discriminative models have inherent differences in feature requirements.
- Modern diffusion models show promise in generating images but have untapped categorization potential.
- Utilizing diffusion models for classification tasks without altering pre-training is effective.
- Diffusion features are compared favorably to other architectures for transfer learning in downstream tasks.
Main AI News:
In the ever-evolving landscape of AI research, learning unified and unsupervised visual representations has remained an arduous task. Within the realm of computer vision, two fundamental categories persist: discriminative and generative. The former involves training models to assign labels to individual images or specific sections of images, while the latter focuses on creating or modifying pictures and performing related operations like inpainting and super-resolution. Bridging the gap between these two approaches is a challenging endeavor, but it holds the key to unlocking novel capabilities in the world of AI.
One of the pioneers in this domain was BigBiGAN, a deep learning technique that attempted to simultaneously tackle both discriminative and generative challenges. However, while BigBiGAN demonstrated early promise, it has been surpassed by more recent methods that employ specialized models with enhanced classification and generation performance. Notably, BigBiGAN suffers from accuracy and Frechet Inception Distance (FID) shortcomings, coupled with high training loads, slower processing, and larger size compared to its counterparts like Generative Adversarial Networks (GANs) with encoders and ResNet-based discriminative approaches.
In this quest for unified representation learners that can excel in both categorization and generation, researchers have made significant strides. Recent studies showcase promising outcomes in generation and categorization, both with and without supervision. Nonetheless, self-supervised representation learning remains an area requiring further exploration, especially when compared to the plethora of works dedicated to supervised image representation learning.
A fundamental challenge lies in the inherent differences between discriminative and generative models. Generative models necessitate representations capable of capturing low-level, pixel-level, and texture features to achieve high-quality reconstruction and creation. On the other hand, discriminative models rely on high-level information to distinguish objects at a coarse level, focusing on the semantics of the image’s content rather than specific pixel values.
Despite these inherent differences, certain techniques like Mean Absolute Error (MAE) and Mean Absolute Gradient Error (MAGE) have demonstrated that models can excel in both low-level pixel information and classification tasks, showcasing the potential of unified representation learning. This brings us to the emergence of modern diffusion models, which have proven remarkably successful in achieving image generation objectives. Nevertheless, their categorization potential remains largely untapped and unexplored.
Researchers from the University of Maryland propose a novel perspective on this matter. Instead of creating unified representation learners from scratch, they advocate leveraging cutting-edge diffusion models, potent image-creation models that inherently possess strong emergent classification capabilities. Their approach yields remarkable results, as depicted in Figure 1, wherein diffusion models outperform BigBiGAN in both picture creation and image categorization.
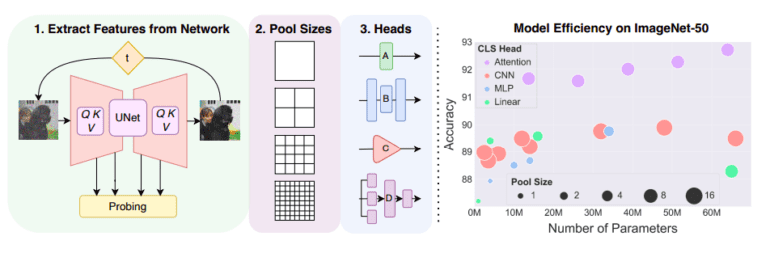
One of the key challenges in utilizing diffusion models lies in selecting appropriate noise steps and feature blocks. This process is intricate, as feature maps can be substantial in terms of channel depth and spatial resolution. To address this, the researchers propose several classification heads that can replace the linear classification layer. This enhances classification results without compromising generation performance or increasing the model’s parameters.
The findings showcase that diffusion models can be effectively employed for classification tasks without necessitating alterations to the diffusion pre-training. They excel as classifiers by extracting adequate feature representations. As a result, this method can be adapted to any pre-trained diffusion model, potentially benefiting from future advancements in model size, speed, and image quality.
Moreover, the researchers delve into the efficacy of diffusion features for transfer learning on downstream tasks, comparing them directly with features from alternative approaches. Fine-grained visual classification (FGVC) is chosen for these downstream tasks due to the scarcity of labeled data for many FGVC datasets. Unlike other studies that rely on color invariances, diffusion-based approaches are particularly suitable for FGVC tasks, as they are not limited by such constraints.
In summary, the contributions of this research are significant:
- Diffusion models, with a remarkable FID of 26.21 (a 12.37 improvement over BigBiGAN) for unconditional image formation and 61.95% accuracy (1.15% better than BigBiGAN) for linear probing on ImageNet, can effectively serve as unified representation learners.
- The study provides essential analysis and distillation guidelines for obtaining the most actionable feature representations from the diffusion process.
- Comparison of attention-based heads, CNN, specialized MLP heads, and standard linear probing showcases the best practices for using diffusion representations in classification scenarios.
- The transfer learning characteristics of diffusion models are extensively examined using various well-known datasets, with a focus on fine-grained visual categorization (FGVC) as a downstream task.
- Comprehensive comparisons utilizing centered kernel alignment (CKA) shed light on the efficacy of diffusion model features relative to alternative architectures and pre-training techniques, as well as different layers and diffusion features.
Conclusion:
These advancements in diffusion models signify a significant stride in the market of AI-powered image classification. The ability of diffusion models to outperform BigBiGAN in both picture creation and categorization tasks positions them as potent unified self-supervised representation learners. This breakthrough holds promising implications for industries reliant on image analysis, such as computer vision, healthcare, autonomous systems, and more. Businesses that incorporate these cutting-edge models into their AI strategies can gain a competitive edge by leveraging superior image classification capabilities and unlocking new possibilities in visual understanding and generation. As the field of AI continues to evolve, diffusion models stand as a beacon of innovation, revolutionizing how AI interprets and interacts with visual data and paving the way for exciting applications and opportunities in the market.