
TL;DR:
- Reinforcement learning (RL) is a popular approach for training autonomous agents through interactions with their environment.
- RL faces challenges in efficiently exploring vast state spaces in real-world problems.
- Large language models (LLMs) offer promising potential in aiding RL agents by providing external knowledge.
- DECKARD, a groundbreaking AI approach, uses LLMs to generate Abstract World Models (AWM) for subgoals.
- DECKARD improves exploration efficiency and sample effectiveness, particularly in Minecraft crafting tasks.
Main AI News:
Reinforcement learning (RL) has proven to be a highly effective approach in training autonomous agents to master complex tasks through dynamic interactions with their environment. By rewarding positive behavior, RL equips agents with the ability to adapt and optimize their actions according to various conditions.
However, one of the most significant challenges faced in RL is efficiently navigating the vast state space of real-world problems. Given that agents learn primarily through exploration, tackling complex environments can be akin to traversing an intricate Minecraft crafting tree with countless craftable objects, each dependent on others for creation. The result? A highly intricate and demanding environment for RL agents to conquer.
Random exploration alone cannot guarantee that an agent will stumble upon the optimal policy in such a vast and complex space. Therefore, there is a need for efficient exploration methods that can effectively balance exploitation and exploration. The quest to find the perfect balance remains an active domain of research in RL.
Practical decision-making systems, as they exist in the real world, heavily rely on prior knowledge about the tasks at hand. Armed with this prior information, an agent can more intelligently adapt its policy, steering clear of sub-optimal decisions. Surprisingly, most RL methods, to date, train without utilizing any external knowledge or previous training.
So, why have we not tapped into the potential of large language models (LLMs) to bolster RL agents’ exploration capabilities? Recent years have witnessed a growing interest in leveraging LLMs to aid RL agents by offering external knowledge. While this approach shows considerable promise, it also presents its fair share of challenges, including effectively grounding LLM knowledge in the environment and addressing the accuracy of LLM outputs.
Despite these hurdles, abandoning LLMs as an aid to RL agents may not be the optimal choice. Instead, the key lies in addressing these challenges head-on and finding ways to reintegrate LLMs as invaluable guides for RL agents. And that’s precisely where DECKARD comes into play.
DECKARD emerges as a cutting-edge solution tailored to the intricate world of Minecraft. Crafting specific items in this virtual realm proves to be a formidable task for those without expert knowledge of the game. Previous studies have demonstrated that achieving goals in Minecraft becomes more manageable with the use of dense rewards or expert demonstrations, highlighting the persistent challenge faced by AI in item crafting.
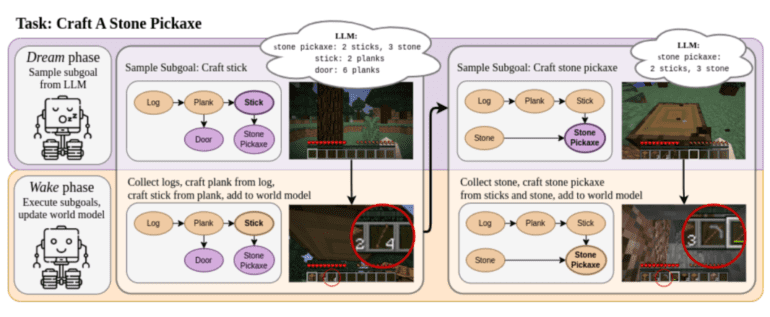
At its core, DECKARD employs a few-shot prompting technique on a large language model (LLM) to create an Abstract World Model (AWM) for subgoals. Through this approach, DECKARD allows the LLM to dream about the task at hand and formulate the necessary steps to accomplish it. Subsequently, during the waking phase, DECKARD learns a modular policy of subgoals that were generated during its dreaming process. The most intriguing aspect is that DECKARD operates in the real environment, enabling it to verify the hypothesized AWM. Any inaccuracies are promptly corrected during this phase, while discovered nodes are marked as verified for future use.
Experimentation has demonstrated that LLM guidance plays a pivotal role in DECKARD’s exploration capabilities. In comparison to an agent without LLM guidance, DECKARD significantly reduces the time required for crafting most items during open-ended exploration. When focused on a specific task, DECKARD showcases unparalleled sample efficiency, outperforming comparable agents by orders of magnitude. This remarkable outcome underscores the potential and robust application of LLMs in the realm of RL.
Conclusion:
DECKARD’s innovative use of large language models (LLMs) to aid reinforcement learning (RL) agents represents a significant advancement in the AI market. By efficiently exploring complex environments and enhancing sample efficiency, DECKARD showcases the immense potential of integrating language models with RL methodologies. This technology can revolutionize decision-making systems across industries, enabling AI agents to tackle real-world challenges with greater adaptability and precision. As businesses seek to optimize their AI-driven processes, DECKARD’s approach opens up new avenues for achieving higher levels of task mastery and problem-solving capabilities.