
TL;DR:
- QLORA is an innovative finetuning approach that drastically reduces memory usage in large language models (LLMs).
- It quantizes pretrained models to 4-bit resolution, and with learnable Low-rank Adapter weights, fine-tuning is achieved without compromising performance.
- QLORA reduces the memory needs for finetuning a 65B parameter model from over 780GB to just 48GB on a single GPU.
- The approach enables fine-tuning large models on a single GPU, making LLM finetuning more accessible.
- The technology is accompanied by advanced data types, double quantization, and paged optimizers to enhance efficiency.
- QLORA’s impact on chatbot performance and instruction finetuning is thoroughly explored, leading to invaluable insights.
- The study highlights the significance of data quality over dataset size for chatbot performance.
- The incorporation of human raters and GPT-4 assessments reinforces the reliability of model-based evaluation.
- QLORA’s contributions are openly shared with the community, offering a collection of adapters and code repositories.
Main AI News:
In the ever-evolving landscape of large language models (LLMs), the process of finetuning has emerged as a pivotal strategy for enhancing performance while incorporating desired behaviors. However, the considerable cost associated with finetuning big models has been a major hurdle, with models like the LLaMA 65B parameter model gobbling up a staggering 780 GB of GPU RAM during standard 16-bit mode finetuning. This exorbitant memory consumption has been a roadblock for researchers and practitioners seeking to harness the full potential of these language models.
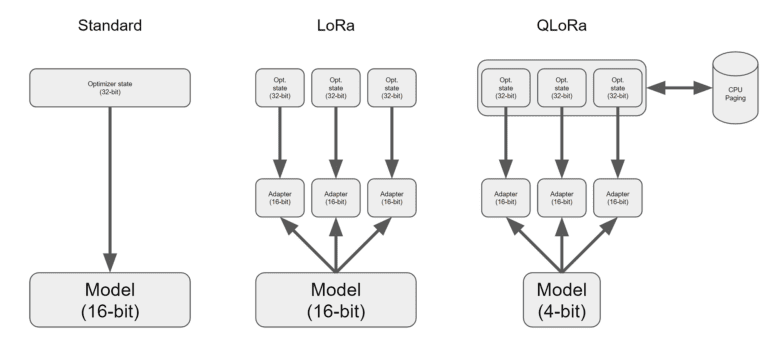
However, there’s a glimmer of hope on the horizon with the groundbreaking development of QLORA by researchers from the University of Washington. QLORA presents an efficient finetuning approach that reduces memory usage to a remarkable extent. This remarkable technique allows the finetuning of a 65B parameter model on a single 48GB GPU, while preserving the full 16-bit fine-tuning task performance.
The key innovation lies in the quantization of a pretrained model using an advanced, high-precision algorithm to a 4-bit resolution. To make this process even more effective, QLORA introduces a sparse set of learnable Low-rank Adapter weights that are intelligently modified by backpropagating gradients through the quantized consequences. What’s truly groundbreaking is that QLORA proves, for the first time, that a quantized 4-bit model can be fine-tuned without sacrificing performance.
Let’s delve into the jaw-dropping results. Compared to a 16-bit fully finetuned baseline, QLORA achieves a remarkable feat – reducing the average memory requirements for finetuning a 65B parameter model from a staggering >780GB of GPU RAM to a mere 48GB, all without compromising runtime or predictive performance. This means that the largest publicly accessible models to date are now fine-tunable on a single GPU, unlocking an unprecedented level of accessibility for LLM finetuning.
The research team puts their findings to the test by training the Guanaco family of models using the QLORA approach. The results are nothing short of awe-inspiring, with their largest model achieving an impressive 99.3% using just a single professional GPU over a mere 24 hours, effectively bridging the gap to ChatGPT on the Vicuna benchmark. Even the second-best model achieves a commendable 97.8% of ChatGPT’s performance on the Vicuna benchmark, all while being trained in less than 12 hours on a single consumer GPU.
What’s the magic behind QLORA’s memory-saving prowess? Let’s explore its ingenious technologies. Firstly, the introduction of “4-bit NormalFloat,” a quantization data type specially designed for normally distributed data, proves to be information-theoretically optimum and delivers superior empirical outcomes compared to conventional 4-bit Integers and 4-bit Floats. Secondly, “Double Quantization” comes into play, saving an average of 0.37 bits per parameter (approximately 3 GB for a 65B model) by quantizing the quantization constants. Lastly, the use of “Paged Optimizers” leverages NVIDIA unified memory to prevent memory spikes caused by gradient checkpointing when processing a mini-batch with an extensive sequence.
The incorporation of these contributions into a refined LoRA strategy that includes adapters at every network tier nearly eliminates the accuracy trade-offs witnessed in earlier work. QLORA’s exceptional efficiency enables an in-depth analysis of instruction finetuning and chatbot performance on model sizes, surpassing what was previously possible with conventional finetuning due to memory constraints. The researchers demonstrate the versatility of their approach by training over a thousand models, encompassing various instruction-tuning datasets, model topologies, and parameter values ranging from 80M to 65B. Their findings illustrate that QLORA effectively restores 16-bit performance, empowers the training of Guanaco, an advanced chatbot, and facilitates the examination of patterns in the learned models.
The research team also brings intriguing insights into the realm of chatbot performance. They discover that data quality takes precedence over dataset size, with a mere 9k sample dataset (OASST1) outperforming a 450k sample dataset (FLAN v2, subsampled) on chatbot performance. Moreover, good Massive Multitask Language Understanding (MMLU) benchmark performance does not always translate into great Vicuna chatbot benchmark performance, and vice versa, emphasizing the significance of dataset appropriateness for a given task. To ensure robust evaluation, the team incorporates human raters and GPT-4 to assess chatbot performance, highlighting that GPT-4 and human judgments generally align, but there are instances of divergence, underlining the uncertainties in model-based assessment compared to the more expensive human annotation.
Expanding the scope further, the researchers supplement their chatbot benchmark findings with qualitative analysis of Guanaco models. This investigation uncovers instances of success and failure that quantitative standards could not account for, providing a comprehensive understanding of model behavior. In a true spirit of academic collaboration, all model generations, along with GPT-4 and human comments, are published to support future research.
Furthermore, the researchers share their techniques with the world, integrating them into the Hugging Face transformers stack and open-sourcing their software and CUDA kernels, making them widely accessible to the community. For a massive leap in open-source offerings, they provide a collection of adapters for 32 distinct models of sizes 7/13/33/65B trained on 8 different instruction following datasets. The entire code repository is made public, alongside a demo that can be hosted on Colab, encouraging wider engagement and experimentation.
Conclusion:
QLORA’s breakthrough in optimizing GPU memory usage for finetuning has far-reaching implications for the language model market. By significantly reducing the memory footprint, it democratizes access to large language models, fostering more extensive research and application possibilities. With QLORA’s efficient techniques, businesses and researchers can now harness the full potential of these models on a more feasible scale, enabling more sophisticated and accessible language-based applications in various industries. The open-source nature of QLORA ensures collaborative growth and advancement, solidifying its position as a transformative force in the language model landscape.