
TL;DR:
- Large Language Models (LLMs) redefine AI complexity, excelling in NLP, NLU, NLG.
- LLMs now interpret human intent, execute intricate tasks.
- AutoGPT, BabyAGI, AgentGPT leverage LLMs for autonomous goals.
- Lack of standardized benchmarks hinders LLMs-as-Agents assessment.
- AgentBench addresses this gap with 8 diverse settings.
- AgentBench evaluates LLMs in coding, knowledge, reasoning, directive adherence.
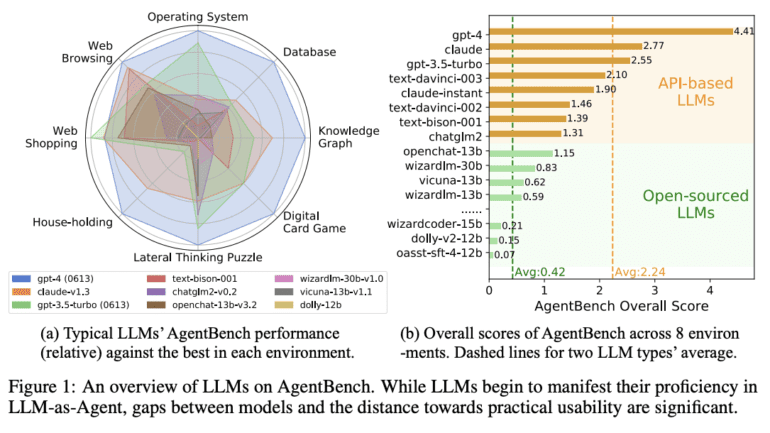
- 25 LLMs analyzed; GPT-4 proficient, API-based models lag behind open-source.
- Open-source LLMs struggle with AgentBench’s intricate tasks.
- Need for enhancing open-source LLMs’ learning capacities.
Main AI News:
The landscape of Artificial Intelligence has been enriched by the emergence and evolution of Large Language Models (LLMs), ushering in a new era of complexity. These models, honed through rigorous training methodologies, have not only demonstrated exceptional prowess in Natural Language Processing (NLP), Natural Language Understanding (NLU), and Natural Language Generation (NLG), encompassing tasks such as question-answering, contextual comprehension, and summarization, but have also ventured into unconventional territories like discerning human intent and executing intricate directives.
The synergy of cutting-edge innovations such as AutoGPT, BabyAGI, and AgentGPT, harnessing the potential of LLMs to accomplish autonomous objectives, owes its existence to the advancements in NLP. While these ventures have garnered considerable public attention, the glaring absence of a standardized foundation for appraising LLMs-as-Agents looms as a formidable impediment. Historical evaluations employing text-based gaming environments, despite their utility, often grapple with limitations emanating from constrained and distinct action sequences. Moreover, their primary focus on assessing models’ ability for grounded commonsense often sidelines other critical attributes.
Many existing benchmarks tailored for assessing agents tend to be environment-specific, curbing their ability to offer a comprehensive evaluation of LLMs within a diverse array of real-world applications. In response to these challenges, a formidable coalition of scholars from Tsinghua University, Ohio State University, and UC Berkeley has unveiled AgentBench—a multidimensional benchmark thoughtfully architected to scrutinize LLMs-as-Agents across a spectrum of scenarios.
AgentBench encompasses an impressive array of eight distinctive settings, five of which stand as groundbreaking additions: lateral thinking puzzles (LTP), knowledge graphs (KG), digital card games (DCG), operating systems (OS), and databases (DB). Additionally, the remaining three environments—housekeeping (Alfworld), online shopping (WebShop), and web browsing (Mind2Web)—draw inspiration from pre-existing datasets. These meticulously crafted scenarios replicate interactive scenarios wherein text-based LLMs are entrusted with the role of autonomous agents. The battery of evaluations rigorously probes core LLM competencies, spanning coding proficiency, knowledge assimilation, logical deliberation, and adherence to directives. Consequently, AgentBench emerges as an exhaustive crucible, adept at evaluating both agents and LLMs.
Leveraging the potent tool of AgentBench, researchers have embarked on a comprehensive exploration, meticulously dissecting and assessing 25 distinct LLMs, spanning both API-based and open-source variants. The findings underscore the prowess of premier models like GPT-4, effectively steering an eclectic array of real-world tasks, thereby envisioning the prospect of cultivating highly proficient, ever-evolving agents. However, notable caveat surfaces—the apex API-based models exhibit perceptible performance deficits when juxtaposed with their open-source counterparts. Notably adept in conventional benchmarks, the open-source LLMs encounter substantial stumbling blocks when confronted with the intricate tasks set forth by AgentBench. This sobering reality amplifies the urgency for concerted endeavors aimed at augmenting the learning acumen of open-source LLMs.
Conclusion:
The unveiling of AgentBench marks a pivotal advancement in assessing Language-Driven Agents. The benchmark’s comprehensive evaluation across multifaceted scenarios offers a critical lens into the capabilities of both top-tier and open-source LLMs. This development will undoubtedly steer AI research and development, fostering a more profound understanding of the potential and limitations of these agents in diverse real-world applications. The disparities observed between API-based and open-source models illuminate the strategic imperative of bolstering the latter’s adaptability and learning potential, reshaping the competitive landscape of the AI market.