
TL;DR:
- Google AI introduces AdaTape, a transformative AI model.
- AdaTape enables dynamic computation in neural networks.
- Unlike fixed functions in conventional models, AdaTape adapts to input complexity.
- Adaptive computation offers inductive bias for complex problem-solving.
- AdaTape employs an adaptive tape reading mechanism for input modification.
- It utilizes a Transformer-based architecture with dynamic token sequences.
- AdaTape’s “tape bank” dynamically selects tape tokens for enhanced adaptability.
- Separate feed-forward networks for input and tokens slightly improve output quality.
- AdaTape outperforms baseline models with recurrence and traditional Transformers.
- Tested on ImageNet-1K, AdaTape balances quality and cost better than alternatives.
Main AI News:
In the realm of artificial intelligence, Neural Networks have long held the promise of revolutionizing our understanding of complex patterns and tasks. Yet, despite their impressive capabilities, they’ve been confined by a rigidity that limits their adaptability to diverse scenarios. Unlike humans, who effortlessly adjust their responses based on context, neural networks execute the same predetermined functions regardless of the intricacies of the input data they encounter.
Recognizing this limitation, researchers at Google AI have unveiled a transformative solution – AdaTape. This groundbreaking model redefines the possibilities of neural network computation by introducing adaptivity, a dynamic paradigm that enables these AI systems to recalibrate their behavior in response to varying environmental conditions. Such adaptivity not only empowers practitioners with unparalleled flexibility in utilizing these models but also provides a powerful inductive bias, enhancing their capacity to tackle even the most complex problem sets.
Traditional neural networks are encumbered by fixed computations and inflexible functions. In contrast, AdaTape empowers models with adaptive and dynamic computation capabilities, allowing them to allocate computational resources based on the complexity of the input data. This approach presents a dual advantage. Firstly, it introduces an inductive bias that tailors the number of computational steps taken for different inputs, a crucial aspect in addressing challenges that involve hierarchical problem-solving. Secondly, it introduces a novel dimension of flexibility in cost-effective inference, as the model can allocate more computational resources to process new inputs with varying levels of intricacy.
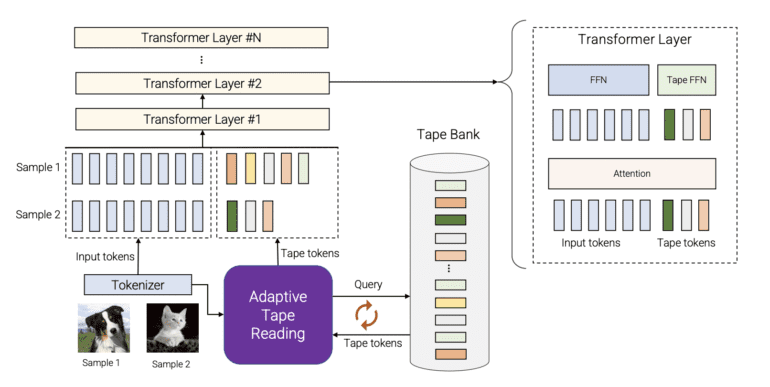
The brainchild of Google’s research team, AdaTape is an elegant manifestation of adaptive computation. Its implementation is elegantly simple: rather than altering the model’s depth, adaptivity is seamlessly infused into the input sequence itself. This approach not only simplifies the implementation process but also maintains a remarkable level of accuracy. At the core of AdaTape’s innovation lies an adaptive tape reading mechanism, a novel approach that appends diverse tape tokens to each input, guided by the input’s inherent complexity.
AdaTape’s foundation is built upon the powerful architecture of the Transformer model. This Transformer-based structure utilizes a dynamic assortment of tokens, resulting in an elastic input sequence that adapts to the data’s intrinsic nature. Further leveraging its adaptive function, AdaTape employs a vector representation for each input, enabling the dynamic selection of variable-sized sequences of tape tokens.
Central to AdaTape’s operation is its “tape bank” – a reservoir of candidate tape tokens that interact seamlessly with the model through the adaptive tape reading mechanism. This dynamic selection process empowers AdaTape to curate a variable-size sequence of tape tokens, enhancing its ability to handle inputs of varying complexities. Two distinct methods were employed to create the tape bank: an input-driven bank, which extracts tokens from the input using a different approach from the conventional model tokenizer, and a learnable bank, a more versatile technique that employs trainable vectors as tape tokens.
Once the tape tokens are fused with the original input, they journey into the heart of the transformer. Here, two dedicated feed-forward networks come into play. One processes the original input, while the other focuses on the tape tokens. This innovative dual-network approach resulted in slightly enhanced output quality, showcasing the meticulous attention to detail exhibited by Google’s researchers.
In the rigorous testing phase, AdaTape exceeded all expectations. It showcased superiority over baseline models incorporating recurrence in their input selection mechanisms. Particularly noteworthy was AdaTape’s innate ability to implicitly maintain a counter – a feat unattainable by standard Transformers. Additionally, AdaTape underwent rigorous evaluation in the realm of image classification tasks. In tests conducted on the demanding ImageNet-1K dataset, AdaTape emerged victorious, demonstrating a remarkable balance between quality and cost that set it apart from alternative adaptive transformer baselines.
Conclusion:
Google AI’s AdaTape marks a significant milestone in AI computation. It is adaptability and dynamic tokenization redefine neural network capabilities, enhancing problem-solving potential and image classification quality. AdaTape’s innovative approach is poised to reshape the AI landscape, offering industries flexible and efficient models that will revolutionize how AI-driven solutions impact the market.