
TL;DR:
- Google introduces Visually Rich Document Understanding (VRDU) dataset for better document comprehension.
- VRDU addresses challenges in complex documents with tables, graphics, and layouts.
- Benchmark criteria formulated for accurate real-world application assessment.
- VRDU models automatically extract structured data like names, addresses, dates, and more.
- Dataset comprises Ad-Buy Forms and Registration Forms collections, meeting all criteria.
- Recent developments include Large-Scale Linguistic Models (LLMs) and few-shot learning techniques.
- VRDU benchmark extends to the research community, aiding evaluation and advancement.
- VRDU’s future holds promise with enhanced VRDU models for diverse business processes.
Main AI News:
In the era of digitalization, enterprises are generating an ever-growing volume of documents. Although these documents often contain valuable insights, their complexity can pose challenges for easy comprehension. Particularly intricate are invoices, forms, and contracts, characterized by visually intricate layouts, intricate tables, and intricate graphics that can impede the extraction of pertinent information.
Addressing this disparity in understanding and bolstering the advancement of document comprehension tasks, Google researchers have proudly introduced the groundbreaking Visually Enriched Document Understanding (VRDU) dataset. Delving into the very documents, that real-world comprehension models encounter, Google lays out five pivotal criteria for a potent benchmark. This trailblazing paper meticulously outlines how prevalent datasets in academic circles fall short in at least one of these key dimensions, while the VRDU dataset outshines the rest in all aspects. Google has now made the VRDU dataset and evaluation code public, accessible under a Creative Commons license.
Pioneering the realm of research, the Visually Enriched Document Understanding (VRDU) initiative strives to decipher these intricate materials automatically. VRDU models deftly extract structured details like names, addresses, dates, and totals from documents, fueling applications in invoice processing, CRM enhancement, and fraud detection, among others.
However, the path for VRDU is not without hurdles. The extensive array of document types presents a formidable challenge, further compounded by the complex patterns and layouts seen in visually enriched documents. VRDU models must adeptly handle imperfect inputs, including typographical errors and data gaps.
Yet, despite these obstacles, VRDU shines as a promising and rapidly evolving domain. VRDU models hold the potential to streamline operations, enhance precision, and reduce costs for enterprises across various sectors.
Recent strides in automation have led to the development of intricate systems that transform intricate business documents into structured entities. Manual data entry is a laborious process, making an automated system that extracts data from receipts, insurance documents, and financial statements a boon for efficiency. Modern models, anchored in the robust Transformer framework, showcase substantial accuracy enhancements. These innovations, including the likes of PaLM 2, are optimizing business procedures. However, the complexities faced in real-world scenarios often remain unreflected in academic datasets, leading to a performance gap between theoretical prowess and practical utility.
Metric Standards
In a rigorous analysis, researchers juxtaposed academic benchmarks (e.g., FUNSD, CORD, SROIE) against the accuracy of cutting-edge models (e.g., FormNet, LayoutLMv2) in real-world scenarios. The findings revealed a significant performance gap between state-of-the-art models and academic benchmarks. This incongruity prompted the formulation of five conditions that a dataset should meet to truly emulate the intricacies of real-world applications.
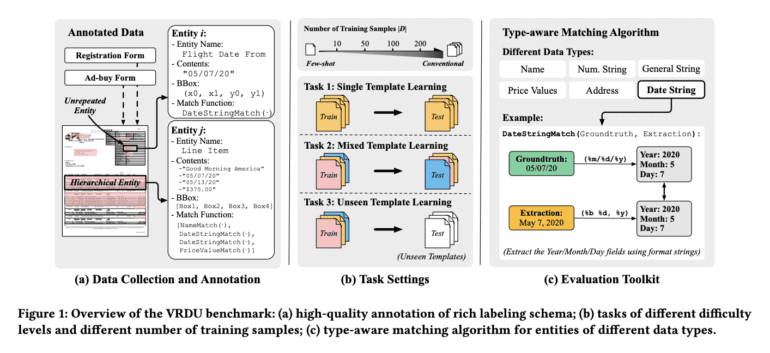
Throughout their exploration, scholars grappled with a variety of rich schemas pertinent to structured extraction. Numeric, textual, temporal, and contextual data all emerge as entities of interest, often necessitating different levels of presence or repetition. To reflect the challenges encountered in practice, extraction operations were conducted over multifaceted schemas, including headers, questions, and answers.
Complex Layout Elements
Documents incorporated in the benchmark must encompass a wide array of layout elements, ranging from tables and key-value pairs to single-column and double-column layouts. The intricate landscape of variable font sizes, captioned images, and footnotes further amplifies the challenge. In contrast, conventional natural language processing benchmarks often focus on sentence, paragraph, and chapter structures with section headers. Templates featuring varying structures play a crucial role in an effective benchmark, as high-capacity models must aptly generalize across different templates/layouts. The benchmark’s train-test split assesses this crucial ability, underscoring its practical significance.
Optical Character Recognition (OCR) outputs must exhibit exceptional quality across all documents. This standard aims to nullify the impact of varying OCR engines on VRDU model performance.
Token-Level Annotation
Crucially, documents must contain meticulously crafted ground-truth annotations, allowing for individual tokens to be mapped back to their corresponding entities within the input text. This strategic departure from standard practice, which usually entails passing along the textual representation of an entity’s value, is pivotal for generating pristine training data. By annotating tokens at the granular level, potential noise stemming from accidental value matches can be circumvented. A case in point: when the tax amount is zero, the ‘total-before-tax’ field on a receipt might coincide in value with the ‘total’ field. Token-level annotations foster accuracy by sidestepping such ambiguities.
VRDU Datasets and Objectives
Within the VRDU ambit lie two distinct publicly accessible datasets—the Registration Forms and Ad-Buy Forms collections. These datasets encapsulate instances germane to real-world contexts while seamlessly adhering to the aforementioned benchmark criteria.
The Ad-Buy Forms collection encompasses 641 files, encapsulating facets of political advertisements. Invoices and receipts have been exchanged between a TV station and an advocacy group. This trove of documents unveils details ranging from product names and air dates to total costs and release timings, embodied through tables, multi-column formats, and key-value pairings.
The Registration Forms collection comprises 1,915 files, meticulously detailing the undertakings of foreign agents registered with the United States government. These documents encapsulate critical information regarding foreign agents’ public engagements, including registrants’ names, affiliated agency addresses, registered activities, and supplementary details.
Recent Leaps in VRDU Advancements
The realm of VRDU has witnessed remarkable progress in recent times. Among the groundbreaking innovations are Large-Scale Linguistic Models (LLMs), which harness large datasets of text and code to represent the intricate textures of text and layout in graphically enriched documents.
A significant feat is the advent of “few-shot learning techniques.” These techniques empower VRDU models to swiftly assimilate information from novel document types, effectively broadening the spectrum of texts within the VRDU purview.
Google Research Extends VRDU Excellence
Google Research takes a pivotal step forward by extending the VRDU benchmark to the global research community. The VRDU standard encompasses visually enriched documents such as invoices and forms. The invoices dataset boasts a repository of 10,000 invoices, while the forms dataset brims with 10,000 forms. The VRDU benchmark not only ushers in a holistic evaluation framework but also equips researchers with an array of robust assessment tools.
The Road Ahead for VRDU
The horizon gleams brightly for VRDU. As Large-Scale Linguistic Models and few-shot learning techniques mature, VRDU models stand to become more robust and adaptable. This evolution unlocks the potential to automate a broader spectrum of business processes, extending their application to diverse document types.
Within the corporate landscape, the impact of VRDU on document comprehension and processing looms large. Virtual Reality Document Understanding (VRDU) not only streamlines document comprehension but also heralds a more accurate and efficient business realm, underscoring its transformative potential.
Conclusion:
The introduction of Google AI’s Visually Rich Document Understanding (VRDU) dataset marks a pivotal advancement in the field of document comprehension. By addressing the complexities of visually intricate documents and offering a comprehensive benchmark for evaluation, VRDU paves the way for more accurate and efficient real-world applications. This has significant implications for the market, as businesses can harness VRDU models to automate processes, boost efficiency, and enhance precision, thereby staying at the forefront of technological evolution and optimizing their operations.