
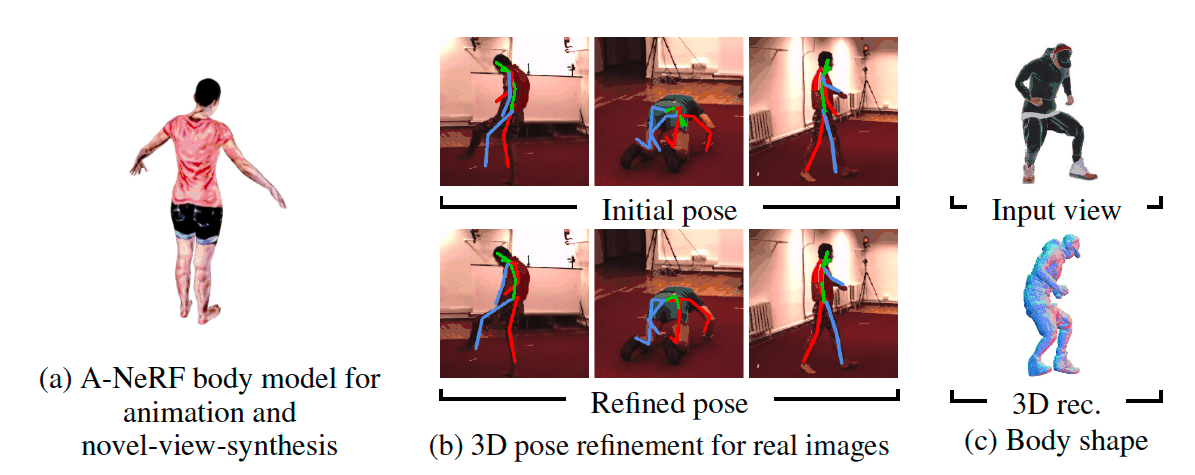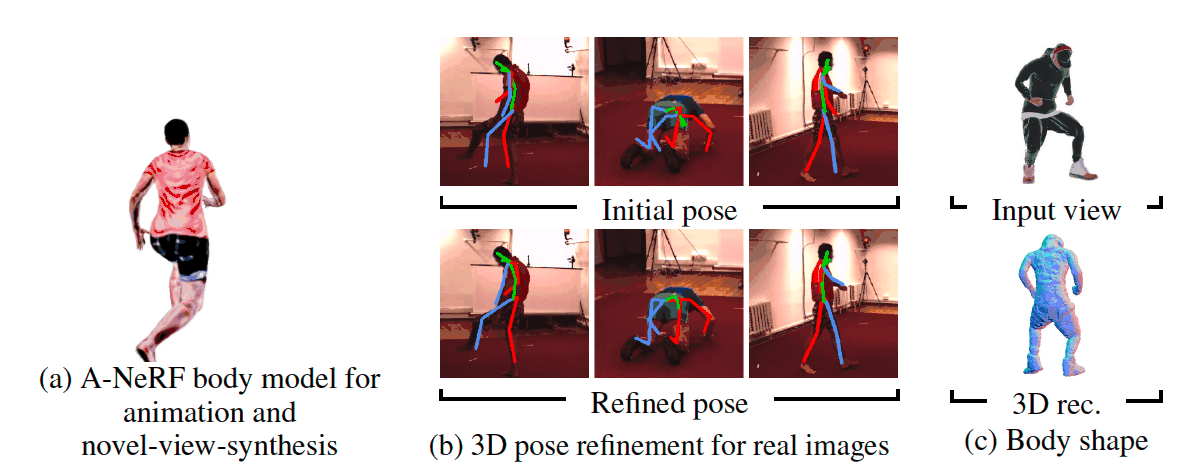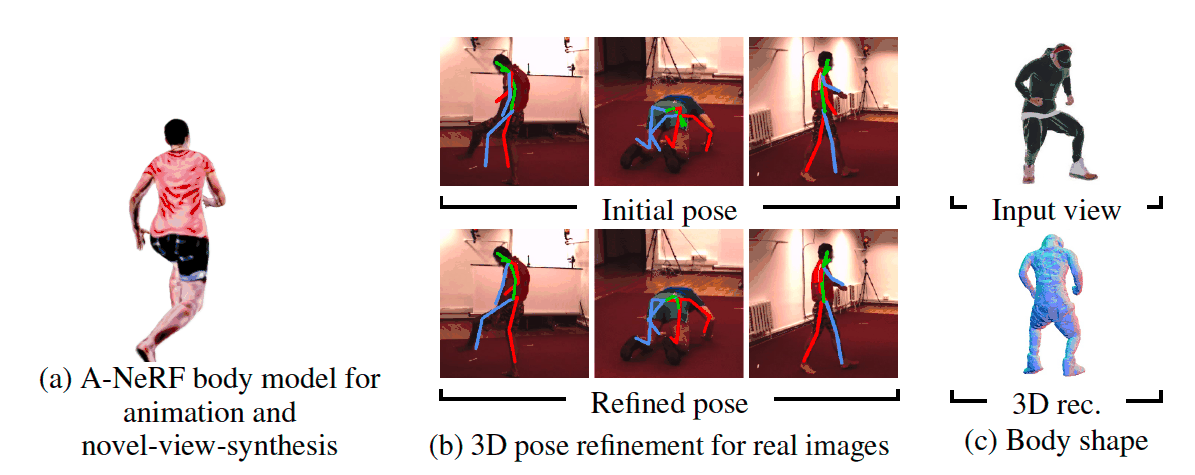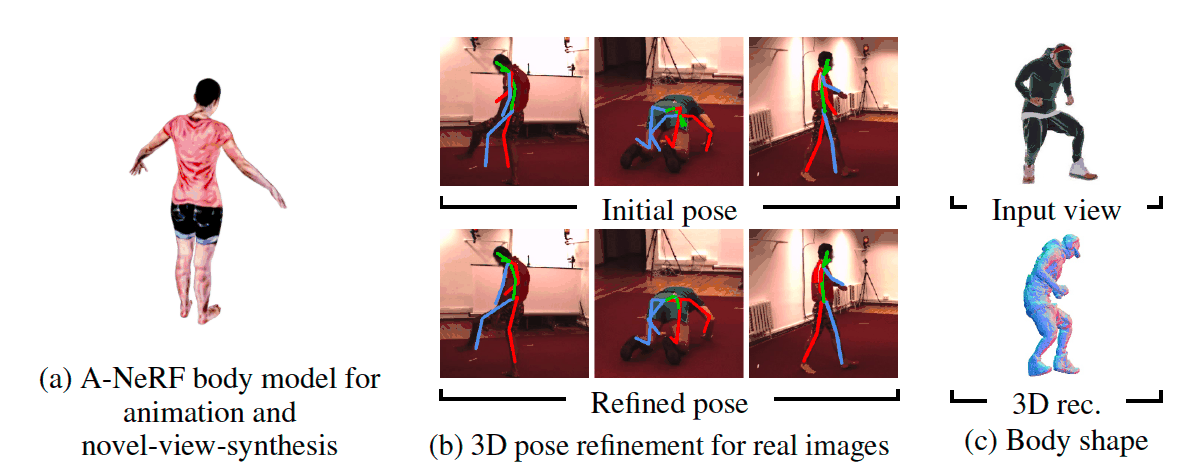
TL;DR:
- AI and Deep Learning advancements lead to Human Neural Radiance Fields (NeRFs) for 3D human modeling.
- SHERF introduces a breakthrough NeRF model recovering 3D human models from a single image.
- SHERF operates in a canonical space, animating models from diverse views and poses.
- Hierarchical features—global, point-level, pixel-aligned—enhance 3D human representation.
- Feature fusion transformer synergizes 3D-aware hierarchical features for comprehensive encoding.
- SHERF surpasses existing methods, demonstrating high generalizability in various datasets.
Main AI News:
In the rapidly evolving landscape of Artificial Intelligence and Deep Learning, remarkable strides have been made, spanning from sophisticated Large Language Models in Natural Language Processing to groundbreaking text-to-image models rooted in Computer Vision concepts. This journey has now led us to the realm of Human Neural Radiance Fields (NeRFs), a groundbreaking avenue that enables the transformation of 2D photos into high-fidelity 3D human models, all without the constraints of precise 3D geometry data. Such advancements carry significant implications, particularly in fields like augmented reality (AR) and virtual reality (VR), reshaping the ways we interact with digital environments.
The advent of Human NeRFs has ushered in an era where crafting intricate 3D human figures from 2D observations is expedited, obviating the need for exhaustive acquisition of ground truth 3D data. The prevailing techniques often rely on monocular films or multi-view cameras capturing 2D photos from diverse perspectives. However, these methodologies falter in real-world scenarios where images are captured from arbitrary camera angles, posing substantial challenges in achieving accurate 3D human reconstructions. Addressing this concern head-on, a pioneering team of researchers introduces SHERF, an avant-garde Human NeRF model that achieves the remarkable feat of recovering animated 3D human models from a solitary input image.
At the heart of SHERF lies its operation within a canonical space, enabling the rendering and animation of reconstructed models from diverse viewpoints and poses. Unlike traditional methods reliant on fixed camera angles, SHERF crafts 3D human representations within a standardized reference frame. These representations ingeniously encapsulate intricate local textures and encompass global appearance information, culminating in a synthesis that embodies both quality and fidelity across viewpoints and positions. This is made possible through the ingenious integration of a bank of 3D-aware hierarchical features, each tailored to facilitate comprehensive encoding.
The hierarchical features comprise three distinct levels: global, point-level, and pixel-aligned. Each tier serves a unique purpose, amplifying the information gleaned from the single input image. Global features work diligently to bridge gaps left by incomplete 2D observations, while pixel-aligned features meticulously safeguard finer details crucial for overall accuracy and realism. Simultaneously, point-level features offer indispensable insights into the underlying 3D human anatomy, lending depth to the reconstructed models.
A pivotal element in this breakthrough is the feature fusion transformer, an ingenious device tailored to synergize the 3D-aware hierarchical features. Engineered to harmonize various feature types, this transformer maximizes the comprehensiveness and informativeness of the encoded representations. Rigorous evaluation across multiple datasets, including THuman, RenderPeople, ZJU_MoCap, and HuMMan, stands a testament to the prowess of SHERF. The results paint a compelling picture: SHERF outperforms current state-of-the-art methodologies, showcasing elevated generalizability in seamlessly amalgamating diverse views and positions.
Conclusion:
In the realm of 3D human modeling, the introduction of SHERF marks a pivotal moment. This innovative approach not only accelerates the creation of high-quality 3D human models from a single image but also tackles the challenges of capturing diverse viewpoints and poses. By combining the power of hierarchical features and a feature fusion transformer, SHERF outperforms existing techniques, underlining its potential to reshape the market dynamics. As industries increasingly integrate augmented reality, virtual reality, and digital environments, SHERF’s capacity to deliver accurate, versatile, and realistic 3D human reconstructions is poised to unlock new avenues of creativity and engagement.