

TL;DR:
- Generative AI’s parallel to human cognition in sparking creativity.
- Emergence of text-to-image models producing lifelike visuals.
- Challenge of guiding models via textual prompts, an alternative approach using visual cues.
- Cross-attention modules in text-to-image diffusion models under scrutiny.
- IP-Adapter, an innovative image prompt solution, introduces a separate cross-attention layer for image features.
- Efficient yet potent, IP-Adapter mirrors fully fine-tuned models with a fraction of the parameters.
- Reusability and adaptability of IP-Adapter across diverse models and controllable adapters.
- Limitation of IP-Adapter: unable to generate images perfectly aligned with thematic essence.
- Future prospects involve developing even more powerful image prompt adapters.
Main AI News:
In today’s tech landscape, the mere mention of “Apple” conjures an immediate mental image of the fruit. The intricacies of human cognition aside, the realm of Generative AI has harnessed a comparable level of ingenuity and prowess. This is the power that fuels machines to birth what we can boldly label as bona fide originality. Recent times have witnessed the emergence of text-to-image models that wield the ability to birth remarkably lifelike visuals. A simple input, such as “apple,” can set these models in motion, conjuring an array of lifelike apple imagery.
Nonetheless, guiding these models to produce our precise visual desires via textual prompts remains a formidable challenge. It demands meticulous sculpting of the right cues. A counter-approach to tackle this challenge lies in the use of visual prompts. While current techniques to fine-tune models from their predecessors have recorded victories, they come at the price of extensive computational might. Furthermore, they struggle to align with diverse base models, textual triggers, and structural refinements.
The forefront of controllable image generation reveals a striking revelation: the cross-attention modules within text-to-image diffusion models warrant a closer inspection. These modules wield custom-calibrated weights to project key and value data within the cross-attention layer of the pre-trained diffusion model. Their primary focus remains the optimization for textual attributes. Yet, the convergence of image and text traits within this layer primarily harmonizes image features with their textual counterparts. Alas, this approach might inadvertently sideline image-specific intricacies, thereby relinquishing a broader realm of control during the creative process – picture managing image style – particularly when leveraging a reference image.
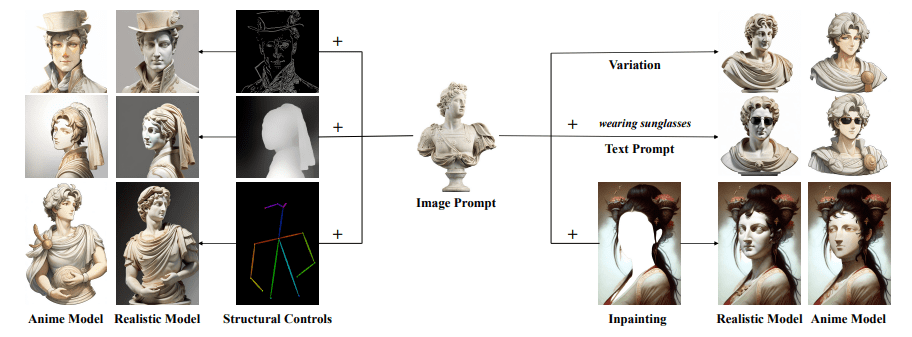
Behold the visual aid above, where the rightmost examples showcase the fruits of image permutations, multimodal synthesis, and image completion through the lens of an image prompt. On the opposing spectrum, the examples on the left depict the outcome of controlled creation utilizing image prompts, coupled with supplementary structural prerequisites.
In response to these complex challenges, enter the IP-Adapter, a groundbreaking image prompt solution crafted by diligent minds. This novel adaptation forges an independent trajectory to address the demands of both textual and visual attributes. Within the diffusion model’s UNet architecture, a distinctive cross-attention layer is seamlessly integrated to cater exclusively to image features. In a feat of ingenious engineering, this auxiliary cross-attention layer undergoes fine-tuning during training, all while keeping the core UNet model unscathed. The sheer elegance of the IP-Adapter lies in its efficiency, all without compromising on potency. Astonishingly, even with a modest 22 million parameters, an IP adapter mirrors the prowess of a meticulously tuned image prompt model derived from the text-to-image diffusion paradigm.
This triumph does not rest solely on efficacy; it carries the banner of reusability and adaptability. The IP-Adapter, birthed within the womb of a foundational diffusion model, metamorphoses into a universal tool, seamlessly accommodating other bespoke models fine-tuned from the same bedrock. Furthermore, its compatibility extends to other controllable adapters, including the esteemed ControlNet. This affords a harmonious fusion of image cues with structural reigns, empowering the creation of multimodal visual marvels.
While the IP-Adapter reigns supreme in most aspects, its prowess finds its boundary in producing images that mirror the essence of reference imagery in content and style. In simpler terms, it might not birth visuals that impeccably adhere to the thematic essence of a provided image, akin to certain existing methods like Textual Inversion and DreamBooth. Gazing into the future, the researchers’ compass points towards the development of even mightier image prompt adapters that shall fortify the edifice of consistency.
Source: Marktechpost Media Inc.
Conclusion:
The introduction of IP-Adapter marks a transformative milestone in the landscape of text-to-image diffusion models. This innovation not only addresses challenges but also opens up new avenues for creativity. With its efficient design and compatibility, the market can anticipate streamlined processes in generating multimodal images, heralding a new era of creative AI applications.