
TL;DR:
- Large Language Models (LLMs) like ChatGPT are shaping AI landscape.
- Fine-tuning LLMs is crucial but memory-intensive due to increased model size.
- Princeton’s MeZO, a memory-efficient zeroth-order optimizer, tackles this issue.
- MeZO adapts ZO-SGD method, estimates gradients using loss differences, conserving memory.
- Designed for billion-parameter LLMs, MeZO is compatible with various parameter tuning approaches.
- MeZO enhances non-differentiable objectives while maintaining memory efficiency.
- Empirical tests reveal MeZO’s effectiveness across diverse model types and downstream tasks.
- MeZO surpasses or rivals existing methods in experiments, consuming less memory.
- MeZO enables training 30B-parameter model on a single GPU, outperforming backpropagation.
Main AI News:
The landscape of Large Language Models (LLMs) has been rapidly evolving, achieving remarkable breakthroughs in Generative Artificial Intelligence (AI) over recent months. These models, heralded by the triumphant ascent of OpenAI’s ChatGPT, have ushered in transformative changes across economic and societal spheres. An emblematic instance of this progress is OpenAI’s ChatGPT, which has captivated millions of users since its inception, with its user base expanding at an exponential pace. Powered by Natural Language Processing (NLP) and Natural Language Understanding (NLU), this chatbot impeccably emulates human-like text generation. With the capacity to meaningfully respond to queries, succinctly summarize extensive passages, and proficiently autocomplete code snippets and emails, ChatGPT stands as a paragon.
In tandem with ChatGPT, other prominent LLMs such as PaLM, Chinchilla, and BERT have exemplified exceptional prowess in the realm of AI. A pivotal approach in leveraging these models has been the fine-tuning of pre-trained language models. This technique empowers these models to acclimate to specialized domains, assimilate human directives, and tailor responses to individual preferences. The essence of fine-tuning resides in calibrating the parameters of a pre-trained LLM using a compact, domain-specific dataset. Yet, as the dimensions of language models burgeon, the process of fine-tuning becomes computationally intricate and memory-intensive, particularly during the computation of gradients in backpropagation. The memory consumption surges, stemming from the necessity to cache activations, gradients, and gradient history – a departure from the frugality observed during inference.
Notably, a group of researchers from the esteemed Princeton University has proffered a pioneering solution to this memory conundrum. Enter MeZO – an ingenious memory-efficient zeroth-order optimizer, a reimagining of the conventional ZO-SGD methodology. Operating in-place, MeZO harnesses the power of estimating gradients through differential loss value measurements. This innovation enables fine-tuning of language models with a memory footprint analogous to that of inference. A strategic emphasis on zeroth-order strategies lends MeZO its memory efficiency, as these methods adeptly deduce gradients through just two forward passes, an attribute tailor-made for conserving memory.
MeZO’s architectural ingenuity is tailored to optimize Large Language Models endowed with billions of parameters. The research team’s cardinal contributions manifest as follows:
- Refined ZO-SGD Paradigm: The cornerstone of MeZO lies in the refinement of the ZO-SGD approach and its associated variants, engineered to operate in situ across models of diverse sizes, while incurring negligible memory overhead.
- Holistic Compatibility: MeZO seamlessly integrates with Progressive Early Stopping Fine-Tuning (PEFT) alongside comprehensive parameter tuning paradigms such as LoRA and prefix tuning, enhancing its adaptability across multifaceted scenarios.
- Diverse Goal Enhancement: MeZO exhibits the remarkable ability to enhance non-differentiable objectives, encompassing accuracy and F1 score, all the while keeping memory utilization at par with inference levels.
- Optimization Efficacy: MeZO’s efficacy in per-step optimization and global convergence hinges upon the condition number of the landscape, signifying the effective local rank. This diverges from prior ZO lower limits, which correlated convergence rate with the sheer volume of parameters.
- Empirical Scaling: Rigorous experimentation unveils MeZO’s prowess across an array of model types, from masked LM to autoregressive LM, with scalability spanning the gamut from 350M to 66B. This agility extends to downstream tasks like classification, multiple-choice, and text generation.
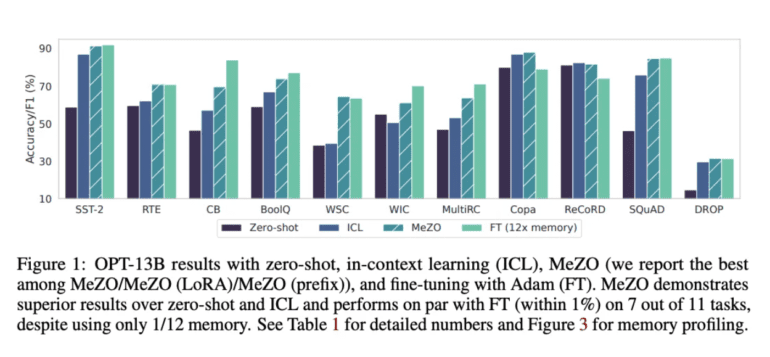
- Benchmark Superiority: Empirical evidence underscores MeZO’s triumph over zero-shot methods, ICL, and linear probing in experiments. Notably, MeZO rivals or outperforms fine-tuning in 7 out of 11 tests with OPT-13B, while impressively demanding approximately 12% less memory than RoBERTa-large or conventional fine-tuning.
In rigorous evaluations, MeZO’s prowess shines. The optimizer efficiently trained a 30-billion parameter model leveraging a solitary Nvidia A100 80GB GPU, a feat that backpropagation, constrained by the same memory limitations, could not replicate for a 2.7-billion parameter LM. In summation, MeZO emerges as an epitome of memory-efficient zeroth-order optimization, poised to revolutionize the fine-tuning of expansive language models.
Conclusion:
Princeton’s MeZO optimizer introduces a transformative solution to the memory-intensive challenge of fine-tuning large language models. Its innovative zeroth-order approach, coupled with compatibility across diverse scenarios, promises heightened efficiency and performance. MeZO’s potential to optimize billion-parameter models while economizing memory usage holds significant implications for the AI market, enabling more efficient and scalable deployment of advanced language models in various applications.