
TL;DR:
- Visual synthesis models are advancing, raising concerns about responsible AI due to the potential misuse of synthesized visuals.
- Responsible visual synthesis faces challenges in adhering to administrator standards and meeting user criteria simultaneously.
- Strategies for responsible visual synthesis include refining inputs, refining outputs, and refining models.
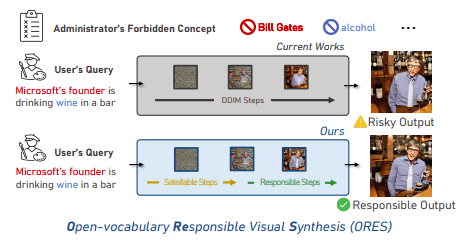
- Microsoft proposes Open-Vocabulary Responsible Visual Synthesis (ORES) with the Two-Stage Intervention (TIN) framework.
- TIN employs CHATGPT to rephrase user queries and diffusion synthesis models for intervention during synthesis.
- The approach enables the avoidance of arbitrary visual elements while aligning with user needs.
- Contextual factors, such as geography and usage circumstances, impact the avoidance of specific visual concepts.
- The ORES approach is a significant step towards addressing open-vocabulary responsible visual synthesis challenges.
Main AI News:
In the realm of visual synthesis, the evolution of expansive model training has ushered in an era of unprecedented realism. In this age, the imperative of Responsible AI looms large, driven by the escalating potential of synthesized visuals. This potential is not without its challenges, particularly when it comes to eradicating specific objectionable elements from synthesized images—elements such as racism, sexual discrimination, and nudity. The complexity of achieving responsible visual synthesis is twofold. Firstly, the synthesis must align with stringent administrative standards, necessitating the exclusion of terms like “Bill Gates” and “Microsoft’s founder.” Secondly, the non-prohibited aspects of a user’s query must be meticulously synthesized to impeccably match the user’s criteria.
Efforts to tackle these challenges are categorized into three main approaches: refining inputs, refining outputs, and refining models. The first strategy, refining inputs, involves pre-processing user queries to conform to administrative requisites. This may involve crafting a blacklist to filter out objectionable content. However, within an open vocabulary environment, achieving the complete elimination of undesirable elements through a blacklist proves to be an intricate task.
The second avenue, refining outputs, delves into post-processing generated visuals to align with administrator guidelines. For instance, the identification and removal of Not-Safe-For-Work (NSFW) content ensure the appropriateness of the output. However, this method grapples with the challenge of identifying open-vocabulary visual concepts, relying on a filtering model pre-trained on specific concepts.
The third and final strategy, refining models, seeks to enhance the model’s alignment with administrative criteria through either holistic or component-specific fine-tuning. This approach bolsters the model’s ability to adhere to prescribed directives, yet biases in the training data can impose limitations, constraining the attainment of open-vocabulary capabilities. This prompts a pivotal question: How can administrators effectively preclude the generation of arbitrary visual concepts while nurturing open-vocabulary responsible visual synthesis?
This quandary is further nuanced by varying contexts, geographical factors, and usage scenarios. The evasion of specific visual concepts necessitates tailored consideration for effective visual synthesis. For instance, if an administrator designates “Bill Gates” or “alcohol” as restricted, the responsible output must articulate concepts akin to everyday language.
Enter Microsoft researchers, who introduce a groundbreaking solution: Open-vocabulary Responsible Visual Synthesis (ORES). This innovation is predicated on the observations above, empowering the visual synthesis model to sidestep arbitrary visual components that haven’t been explicitly prohibited. At the heart of this paradigm is the Two-stage Intervention (TIN) structure, designed to artfully circumvent these challenges. TIN adopts a two-fold approach: 1) rewriting with instructive augmentation through a large-scale language model (LLM) and 2) rapid intervention during synthesis via a diffusion synthesis model.
Under the tutelage of a learnable query, TIN harnesses the prowess of CHATGPT to rephrase the user’s inquiry into a query devoid of risk. In the intermediary synthesis stage, TIN intercedes in the synthesis process, substituting the user’s query with its de-risked counterpart. The outcome is a pioneering benchmark fortified by baseline models, the BLACK LIST, NEGATIVE PROMPT, and an accessible dataset. Merging the capacities of large-scale language models and visual synthesis models, Microsoft’s researchers pioneer the exploration of responsible visual synthesis in an open-vocabulary milieu.
Conclusion:
Microsoft’s pioneering Open-Vocabulary Responsible Visual Synthesis (ORES) approach, coupled with the innovative Two-Stage Intervention (TIN) framework, holds promising implications for the market. This development not only enhances the quality of synthesized visuals but also ensures alignment with diverse user requirements. As responsible AI gains precedence, businesses catering to visual content creation and AI-driven solutions will need to consider and adopt such frameworks to maintain ethical standards and meet evolving user expectations.