
TL;DR:
- Recent advancements apply deep neural networks to enhance search in machine learning, emphasizing representation learning in bi-encoder architecture.
- Content like queries, passages, and multimedia is transformed into meaningful embeddings as dense vectors.
- Dense retrieval models built on this architecture enhance large language models’ capabilities.
- Startups promote “vector stores” as essential components in enterprise architecture.
- Lucene, an open-source search library, remains dominant in production infrastructure.
- Research demonstrates the feasibility of using OpenAI embeddings with Lucene for vector search.
- Embedding APIs simplify generating dense vectors, making them accessible.
- The market may see a shift toward Lucene-based vector search as an efficient solution.
Main AI News:
In recent times, the realm of machine learning has witnessed remarkable advancements, particularly in the integration of deep neural networks into the field of search. A pivotal focus lies on the concept of representation learning within the bi-encoder architecture. This sophisticated framework adeptly transmutes diverse content types, spanning queries, passages, and even multimedia, such as images, into compact yet profound “embeddings,” eloquently portrayed as dense vectors. These potent retrieval models, founded upon this architectural innovation, lay the foundation for augmenting the retrieval processes within expansive language models (LLMs). This methodology has garnered substantial acclaim, proving itself to be an instrumental catalyst in bolstering the overarching capabilities of LLMs, contributing significantly to the domain of generative AI today.
It is widely posited that enterprises, in response to the burgeoning demand to manage numerous dense vectors, should strategically integrate a dedicated “vector store” or “vector database” into their AI infrastructure. A burgeoning niche market of startups zealously advocates these vector stores as pioneering and indispensable components of contemporary enterprise architecture. Eminent examples include Pinecone, Weaviate, Chroma, Milvus, and Qdrant, among others. Some zealous proponents even speculate that these vector databases have the potential to supplant the traditional relational databases that have long been the bedrock of data management.
However, this paper introduces a counterpoint to this prevailing narrative. The arguments herein are underpinned by a pragmatic cost-benefit analysis, taking into consideration the fact that search functionalities already constitute a well-established domain within numerous organizations. These organizations have made substantial investments in fortifying their search capabilities. The production infrastructure is predominantly underpinned by the expansive ecosystem revolving around the open-source Lucene search library, notably propelled by platforms such as Elasticsearch, OpenSearch, and Solr.
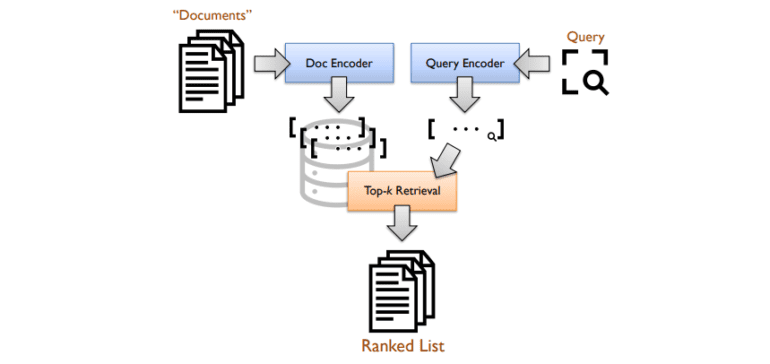
The diagram above elucidates the architecture of a standard bi-encoder system, wherein encoders adeptly generate dense vector representations (embeddings) from both queries and documents (passages). Retrieval is cast as a k-nearest neighbor quest within the vector space. The experimental focus of this study was the MS MARCO passage ranking test collection, meticulously curated from a corpus comprising approximately 8.8 million passages meticulously extracted from the vast expanse of the web. The experimentation incorporated standard development queries along with queries hailing from the TREC 2019 and TREC 2020 Deep Learning Tracks for comprehensive evaluation.
Conclusion:
The integration of Lucene with OpenAI embeddings presents a powerful vector search solution. The market may witness a transition towards this approach, as it leverages existing infrastructure while embracing the benefits of modern AI-driven search capabilities. This fusion of established and innovative technologies holds promising implications for businesses seeking efficient and effective search solutions.