
TL;DR:
- YaRN, a novel method, extends context windows for language models.
- Large language models can now capture complex relationships and dependencies over broader spans of text.
- Rotary position embedding (RoPE) enhances the model’s ability to handle sequential data and positional information.
- YaRN reduces training steps to 0.1% of the original, making it highly compute-efficient.
- It outperforms existing RoPE methods and replaces traditional positional information with ease.
- Fine-tuned models maintain their prowess across various benchmarks.
- Future prospects include memory augmentation for even more contextual understanding.
Main AI News:
Large language models, such as the renowned chat GPT, have revolutionized the field of natural language processing by their ability to grasp extensive contextual information. This profound comprehension empowers them to generate responses that are not only coherent but also contextually meaningful. In the realm of text completion and document understanding, this capability proves invaluable.
These models excel in unraveling intricate relationships and dependencies, even when they span a multitude of tokens. The pivotal concept in this context is the extension of the context window, a term used to define the range of text or tokens that the model takes into account when processing language. This is a critical feature for tasks like document summarization, where a comprehensive grasp of the document is paramount.
Rotary position embedding (RoPE) has been a breakthrough in enhancing models’ capacity to work with sequential data and encode positional information within sequences. Nevertheless, these models must transcend the sequence length they were initially trained on to be fully effective. Enter “YaRN” (Yet another RoPE extension method), a novel innovation by researchers at Nous Research, Eleuther AI, and the University of Geneva.
YaRN introduces a computationally efficient approach to expanding the context window of such models. Leveraging complex number rotations, RoPE allows the model to encode positional information dynamically, reducing its reliance on fixed positional embeddings. This innovation significantly enhances the model’s capability to capture long-range dependencies with precision. The parameters governing these rotations are acquired through the model’s training process, enabling adaptive adjustments to capture positional relationships optimally.
The methodology adopted by the researchers involves “compressive transformers.” These transformers employ external memory mechanisms to extend their context window. By storing and retrieving information from an external memory bank, they transcend their standard window size, thus gaining access to a broader context. This architectural extension, featuring memory components, empowers the model to retain and utilize information from past tokens or examples.
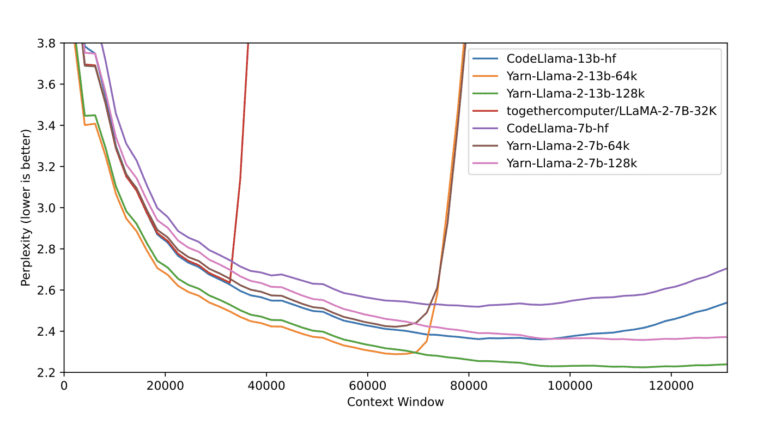
The results of their experiments are remarkable. YaRN achieves a context window extension for Large Language Models (LLMs) with a mere 400 training steps, constituting a mere 0.1% of the model’s original pre-training corpus. This represents a staggering 10-fold reduction from previous methods requiring 25 times more steps and a 2.5-fold reduction compared to 7. Importantly, this efficiency comes with no additional inference costs.
In essence, YaRN not only surpasses all existing RoPE interpolation methods but also replaces traditional positional information (PI) with minimal implementation efforts and no downsides. Fine-tuned models retain their original prowess across multiple benchmarks while now being able to attend to an exceptionally vast context size.
The implications of YaRN extend beyond its groundbreaking context window expansion. Future research endeavors could explore memory augmentation, a concept ripe for integration with conventional NLP models. This synergy could empower transformer-based models to incorporate external memory banks, effectively storing contextually relevant information for downstream tasks like question-answering and machine translation.
Conclusion:
YaRN’s efficient context expansion has significant implications for the market, offering improved language model performance with reduced computational overhead. This innovation promises to enhance the capabilities of natural language processing technologies, making them more accessible and cost-effective for various applications across industries.