
TL;DR:
- DeepMind’s groundbreaking approach, “Large Language Models as Optimizers.”
- Introducing Optimization by PROmpting (OPRO), using large language models as intelligent optimizers.
- LLMs generate optimization solutions from natural language task descriptions.
- OPRO’s unique approach eliminates the need for traditional, formal problem definitions.
- Meta-prompts empower LLMs to iteratively generate and evaluate solutions.
- Objective: Formulate a prompt that maximizes task accuracy.
- Empirical results show OPRO’s remarkable performance on various LLMs.
- Outperformed human-designed prompts by over 50% on certain benchmarks.
Main AI News:
Optimization in the modern world is a critical element in solving complex real-world challenges. However, conventional optimization algorithms often require extensive manual fine-tuning to adapt to specific tasks, grappling with the complexities of decision spaces and performance landscapes.
To address this challenge head-on, a pioneering research team at Google DeepMind has introduced a revolutionary approach, as detailed in their recent paper, “Large Language Models as Optimizers.” This innovative method, known as Optimization by PROmpting (OPRO), harnesses the immense capabilities of large language models (LLMs) to act as intelligent optimizers. These LLMs possess the unique ability to generate optimization solutions based on natural language descriptions of the task at hand.
The extraordinary capacity of LLMs to comprehend natural language opens up exciting new possibilities for generating optimization solutions directly from verbal problem descriptions. Instead of following traditional methods that rigidly define optimization problems and employ pre-programmed solvers to calculate solution steps, this research charters a distinctive course. Here, researchers steer the optimization process by instructing the LLM to iteratively generate fresh solutions guided by natural language instructions and previously discovered solutions.
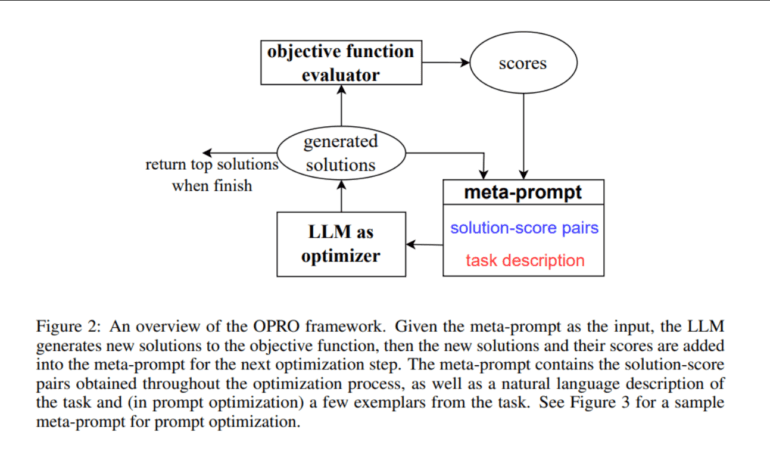
To provide an overview of the OPRO framework, a meta-prompt is utilized, encompassing both the problem’s description and previously evaluated solutions. This meta-prompt serves as input, empowering the LLM to generate candidate solutions informed by the provided data. Subsequently, these newly generated solutions are evaluated and integrated into the meta-prompt for subsequent optimization iterations. This iterative optimization process continues until the LLM cannot propose solutions with higher scores or reach the maximum number of optimization steps. In essence, the ultimate goal is to formulate a prompt that maximizes task accuracy.
In their empirical investigation, the research team rigorously tested the OPRO framework across various LLMs, including text-bison, Palm 2-L, gpt-3.5-turbo, and gpt-4. Remarkably, on small-scale traveling salesman problems, OPRO showcased performance on par with meticulously crafted heuristic algorithms. It even outperformed human-designed prompts by a substantial margin on GSM8K and Big-Bench Hard, achieving over a remarkable 50% improvement.
Conclusion:
DeepMind’s innovative approach, utilizing large language models as intelligent optimizers through OPRO, is set to revolutionize optimization in business strategies. This breakthrough promises to streamline and enhance decision-making processes, offering a competitive advantage to organizations across diverse industries by achieving remarkable performance improvements in optimization tasks.