
TL;DR:
- Large Language Models (LLMs) like GPT-4 have excelled in diverse language tasks.
- Vision Language Models (VLMs) bridge language and visual understanding.
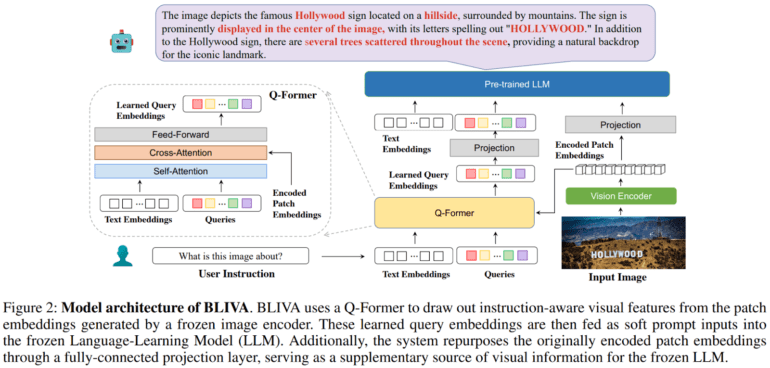
- BLIVA (InstructBLIP with Visual Assistant) integrates query embeddings and image-encoded patch embeddings.
- BLIVA enhances text-image understanding, overcoming limitations in text interpretation within images.
- The model employs a two-stage training paradigm.
- Unfreezing the vision encoder leads to knowledge loss.
- Simultaneous training of the LLM complicates the process without substantial benefits.
Main AI News:
In the dynamic landscape of natural language understanding, Large Language Models (LLMs) have emerged as undisputed champions, flexing their linguistic muscles across an expansive array of tasks. Their prowess extends from zero-shot marvels to navigating the intricacies of few-shot challenges. However, it’s the fusion of textual finesse and visual acumen that propels Vision Language Models (VLMs) into the limelight. Notably, OpenAI’s GPT-4, unveiled in 2023, serves as a beacon, illuminating the path to conquering the enigmatic realm of open-ended visual question-answering (VQA).
Visual question-answering, a domain where a model must decipher questions pertaining to images, has long been a litmus test for AI capabilities. The synergy of LLMs with visual comprehension skills has accelerated progress in this arena. Strategies vary, with some models aligning directly with visual encoders’ patch features, while others extract image insights via a finite set of query embeddings.
Yet, amid the grandeur of image-based interactions, a formidable challenge looms – the interpretation of text within images. Text-laden visuals are ubiquitous in our daily lives, and the ability to decipher them is pivotal for holistic visual cognition. Past endeavors incorporated abstraction modules with queried embeddings but fell short in capturing the intricate nuances of textual elements embedded within images.
In this article, we delve into a groundbreaking study that ushers in a new era of multimodal language models – BLIVA, short for InstructBLIP with Visual Assistant. This meticulously crafted LLM integrates two pivotal components: query embeddings harmoniously interwoven with the LLM and image-encoded patch embeddings brimming with extensive image-related information.
BLIVA heralds a paradigm shift, effectively dismantling the shackles that often hinder language models when processing image data. This breakthrough culminates in an enriched synergy between textual and visual elements, elevating text-image understanding to unprecedented heights. The model’s genesis involves the utilization of a pre-trained InstructBLIP and the construction of an encoded patch projection layer from scratch.
A two-stage training approach guides BLIVA’s evolution. The initial phase revolves around the pre-training of the patch embeddings projection layer, followed by fine-tuning of both the Q-former and the patch embeddings projection layer using instruction tuning data. Remarkably, during this phase, both the image encoder and LLM remain in a frozen state. This strategic decision stems from two pivotal insights gleaned from rigorous experimentation: unfreezing the vision encoder results in catastrophic knowledge loss, and concurrent training of the LLM introduces substantial complexities without commensurate benefits.

Source: Marktechpost Media Inc.
Conclusion:
The advent of BLIVA marks a pivotal moment in the intersection of language and visual processing. This groundbreaking multimodal language model is poised to reshape industries that rely on text-rich visual content, from marketing and advertising to healthcare and education. BLIVA’s ability to bridge the gap between text and images will unlock a new era of innovation and efficiency in the market, offering businesses a competitive edge in content interpretation and customer engagement.