
TL;DR:
- MIT and Microsoft collaborate to introduce DoLa, a groundbreaking AI decoding strategy.
- Large language models (LLMs) suffer from hallucinations, producing inconsistent information.
- DoLa employs contrastive decoding by leveraging knowledge from deeper layers to reduce hallucinations.
- Experimental results demonstrate DoLa’s effectiveness in improving factual accuracy.
- DoLa adds minimal processing time, making it a practical solution for LLMs.
- The research highlights the need for future work in other domains and fine-tuning possibilities.
Main AI News:
Natural language processing (NLP) has witnessed remarkable advancements thanks to the utilization of large language models (LLMs). These LLMs, while progressively improving in performance and versatility, grapple with a persistent challenge – the tendency to generate information that deviates from established real-world facts acquired during pre-training. This propensity poses a formidable hurdle, particularly in high-stakes domains like healthcare and legal contexts, where the production of trustworthy textual content is imperative.
The root of LLMs’ hallucination quandary may well lie in the pursuit of the maximum likelihood language modeling target. This objective, which aims to minimize the forward Kullback-Leibler (KL) divergence between data and model distributions, can inadvertently lead LLMs to assign non-zero probabilities to phrases that do not align entirely with the knowledge ingrained in their training data.
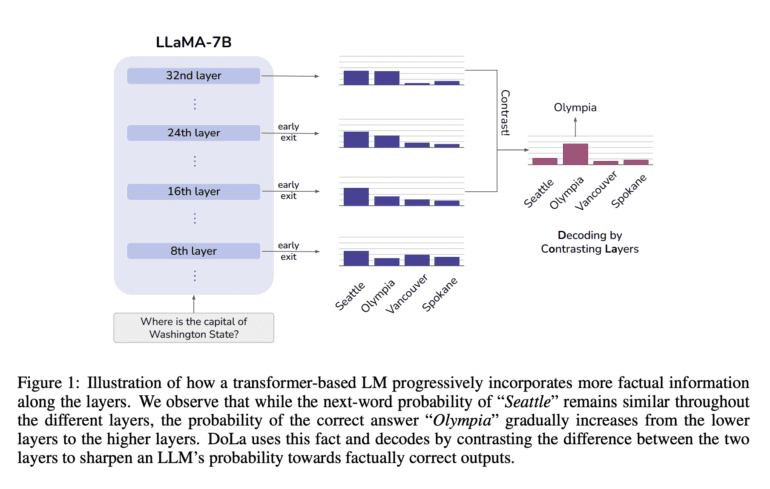
From an interpretability perspective, research indicates that the initial layers of transformer LLMs are repositories of “lower-level” information, encompassing elements like part-of-speech tags. Conversely, the subsequent layers house more “semantic” knowledge.
Enter a team of researchers from the prestigious MIT and tech giant Microsoft, proposing an ingenious solution. They advocate harnessing this modular encoding of knowledge to bolster the factual acumen of LLMs through a contrastive decoding strategy. This strategy calculates the likelihood of the next word’s output by analyzing the disparities in logits from a higher model layer. The outcome? LLMs are grounded more firmly in reality, with a reduced propensity for hallucinations, as the emphasis shifts towards information from deeper layers, while tempering that from intermediate or shallower strata.
Their groundbreaking work unveils “Decoding by Contrasting Layers” (DoLa), an inventive decoding approach that significantly augments the exposure of factual knowledge embedded within an LLM, all without the need for external knowledge retrieval or extensive fine-tuning.
DoLa’s efficacy is substantiated through a series of experiments, affirming its positive impact on LLaMA family models across TruthfulQA and FACTOR. Furthermore, assessments in StrategyQA and GSM8K cc domains, focusing on chain-of-thought reasoning, underscore its potential for enhancing factual reasoning. In a telling revelation, experimental outcomes in open-ended text generation, assessed with GPT-4, underscore DoLa’s ability to craft informative and notably more factual responses, consequently yielding superior ratings compared to conventional decoding methods. What’s more, DoLa achieves this while incurring only minimal additional processing time, reinforcing its practicality.
It’s important to note that this research does not delve into the model’s performance across other domains, such as compliance with instructions or responsiveness to human feedback. Furthermore, the research team abstains from relying on human labels or external factual sources for fine-tuning, opting instead to leverage the existing architecture and parameters, thereby delineating the potential for further enhancements. In stark contrast to certain retrieval-augmented LLMs, DoLa hinges exclusively on the model’s preexisting knowledge, eschewing the incorporation of new information through external retrieval modules. The researchers anticipate future work that harmoniously integrates these elements into their decoding technique, thus transcending current limitations and charting new frontiers in AI-driven language models.
Conclusion:
The introduction of DoLa signifies a pivotal advancement in mitigating hallucinations within large language models. This innovation has the potential to significantly enhance the accuracy and reliability of AI-generated content, particularly in high-stakes industries. However, further exploration into diverse domains and fine-tuning avenues is essential to unlock its full market potential.