
TL;DR:
- China’s Oceanlite Supercomputer is a finalist for the prestigious Gordon Bell Prize.
- Researchers at China’s National Supercomputing Center in Wuxi published a groundbreaking paper on their work.
- The Oceanlite system boasts over 100,000 custom SW26010-Pro processors.
- The machine achieves a theoretical peak performance of 1.5 exaflops.
- Potential for Oceanlite to outperform other supercomputers in the future.
- Several other noteworthy finalists for the Gordon Bell Prize in 2023.
Main AI News:
In the realm of advanced computing, China’s National Supercomputing Center in Wuxi is making headlines yet again. The Association for Computing Machinery recently unveiled the finalists for the prestigious Gordon Bell Prize, set to be awarded at the SC23 supercomputing conference in Denver. Unsurprisingly, the world’s most formidable computing powerhouses are vying for this coveted recognition, all in pursuit of groundbreaking achievements in computation.
While the exact specifications and outcomes of these cutting-edge simulations and models are still pending, one particular revelation has already caught our attention. Researchers at China’s National Supercomputing Center in Wuxi have offered a sneak peek into their work by publishing a paper titled “Towards Exascale Computation for Turbomachinery Flows.” This groundbreaking research leveraged the “Oceanlite” supercomputing system, a name we first encountered back in February 2021 when it clinched the Gordon Bell Prize for a quantum simulation across a staggering 41.9 million cores. Our curiosity about the machine’s configuration was further piqued in March 2022 when Alibaba Group, Tsinghua University, DAMO Academy, Zhejiang Lab, and Beijing Academy of Artificial Intelligence harnessed it to run a pretrained machine learning model, BaGuaLu, across over 37 million cores, boasting an astonishing 14.5 trillion parameters.
Almost a decade ago, NASA issued a formidable challenge: to perform a time-dependent simulation of an entire jet engine, encompassing detailed aerodynamics and heat transfer calculations. The Wuxi team, in collaboration with engineering researchers from various universities in China, the United States, and the United Kingdom, embraced this challenge with vigor. What makes their achievement even more intriguing is that it aligns with our earlier speculations about the Oceanlite machine.
According to the authors of the paper, the system featured an impressive array of over 100,000 custom SW26010-Pro processors, meticulously designed by China’s National Research Center of Parallel Computer Engineering and Technology (NRCPC) for the Oceanlite system. Notably, the SW26010-Pro processor is etched using 14-nanometer processes at China’s national foundry, Semiconductor Manufacturing International Corp (SMIC).
The lineage of the Sunway chip family traces its inspiration to the legendary 64-bit DEC Alpha 21164 processor, renowned as one of the finest CPUs ever created. The 16-core SW-1 chip made its debut in China as far back as 2006.
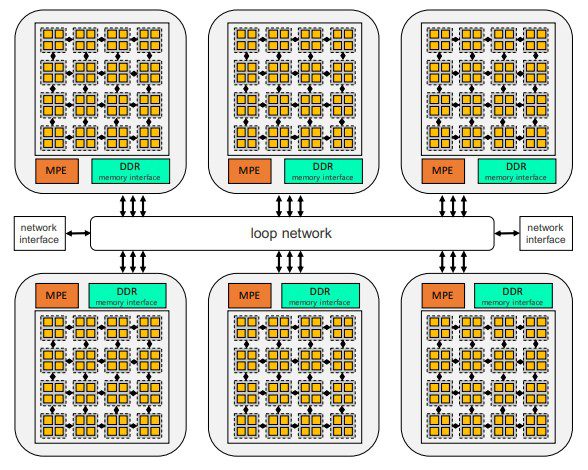
Each processor comprises six core groups, with each core group featuring a robust management processing element (MPE) responsible for handling Linux threads and an eight-by-eight grid of cores, housing a compute processing element (CPE) equipped with 256 KB of L2 cache. Each CPE boasts four logic blocks, facilitating FP64 and FP32 calculations on one pair and FP16 and BF16 computations on another pair. Moreover, every core group within the SW26010-Pro is equipped with a DDR4 memory controller and 16 GB of memory, boasting a remarkable memory bandwidth of 51.4 GB/sec. Consequently, the entire device boasts an impressive 96 GB of main memory and a substantial memory bandwidth of 307.2 GB/sec. To connect the six CPEs, a ring interconnect is employed, complemented by two network interfaces that seamlessly link the system to the external world via a proprietary interconnect—a design concept reminiscent of InfiniBand technology, which was first popularized by the original TaihuLight supercomputer. In terms of performance, the SW26010-Pro chip delivers an impressive 14.03 petaflops at both FP64 and FP32 precision and a remarkable 55.3 petaflops at BF16 or FP16 precision.
To date, the largest reported Oceanlite configuration boasted 107,520 nodes, with each node comprising one SW26010-Pro processor, resulting in a staggering 41.93 million cores spread across 105 cabinets. The recent paper confirmed that the machine achieved a theoretical peak performance of 1.5 exaflops, aligning closely with our earlier estimate of 1.51 exaflops and almost perfectly matching the anticipated clock speed of 2.2 GHz we projected nearly two years ago. Notably, the MPE cores operate at 2.1 GHz, while the CPW cores run at 2.25 GHz.
Yet, we remain convinced that China may have even grander plans for the Oceanlite machine. With a configuration spanning 120 cabinets, the machine’s peak performance could potentially reach 1.72 exaflops at FP64 precision, a figure that narrowly surpasses the 1.68 exaflops anticipated for the “Frontier” supercomputer at Oak Ridge National Laboratory. Furthermore, with 160 cabinets, Oceanlite could conceivably attain just under 2.3 exaflops at FP64 precision. Intriguingly, the Wuxi team is scheduled to present the Oceanlite machine during an upcoming session at SC23 in November. The session’s description hints at a machine boasting 5 exaflops of mixed precision performance across 40 million cores, suggesting a 2.5 exaflops peak performance at FP64 and FP32 precision.
These figures take on added significance when viewed in the context of China’s ambitions to potentially outperform the upcoming “El Capitan” machine at Lawrence Livermore National Laboratory, which is poised to deliver in excess of 2 exaflops of FP64 processing power.
In the latest Gordon Bell prize contender, the team tackled the formidable task of conducting a time-dependent simulation of an entire jet engine, accounting for both aerodynamics and heat transfer. This ambitious endeavor was carried out on Oceanlite, utilizing approximately 58,333 nodes—equivalent to over 350,000 MPE cores and more than 22.4 million CPE cores. Interestingly, the sustained performance of this application reached 115.8 petaflops, shedding light on the machine’s remarkable capabilities.
Among the 2023 Gordon Bell Prize finalists, the University of Michigan and the Indian Institute of Science, in collaboration with Oak Ridge’s Frontier system, stood out. Their innovative approach combined hybrid machine learning with HPC simulations to address complex quantum particle simulations. While the exact performance figures remain pending, it is expected to surpass 650 petaflops, depending on the computational and network efficiencies of the Frontier system for this specific application.
Another finalist comprises researchers from Penn State and the University of Illinois, collaborating with teams at Argonne National Laboratory and Oak Ridge. Together, they embarked on a simulation journey inside a nuclear reactor, encompassing radiation transport with heat and fluid dynamics. Notably, this simulation ran on 8,192 nodes within the Frontier system, officially equipped with 9,402 nodes, each featuring a custom “Trento” Epyc CPU and four “Aldebaran” Instinct MI250X GPU accelerators, resulting in a grand total of 37,608 GPUs.
The fourth contender for the 2023 Gordon Bell Prize features teams from KTH Royal Institute of Technology, Friedrich-Alexander-Universität, Max Planck Computing and Data Facility, and Technische Universität Ilmenau. They achieved remarkable results by scaling Neko, a high-fidelity spectral element code, across 16,384 GPUs within the “Lumi” supercomputer in Finland and the “Leonardo” supercomputer in Italy.
An intriguing collaboration between King Abdullah University of Science and Technology and Cerebras Systems caught our attention, as they harnessed a cluster of 48 CS-2 wafer-scale systems from Cerebras, boasting a total of 35.8 million cores. Notably, this endeavor showcased the fusion of AI matrix mathematics with high-performance computing, a concept we have closely followed.
In the sixth installment of the 2023 finalists, Harvard University took center stage. They leveraged the “Perlmutter” hybrid CPU-GPU system at Lawrence Berkeley National Laboratory to simulate the atomic structure of an HIV virus capsid, spanning an impressive 44 million atoms and several nanoseconds of simulation. Their achievement showcases the ability to scale simulations to a remarkable 100 million atoms.
This year, the ACM introduced the inaugural Gordon Bell Prize for Climate Modeling, and one contender we eagerly anticipated was the SCREAM variant of the Energy Exascale Earth System Model (E3SM), developed and extended by Sandia National Laboratories. SCREAM stands out for its unique approach, involving C++ and the Kokkos library to distribute code efficiently across both CPUs and GPUs. In this instance, it was executed on the Frontier machine at Oak Ridge, enabling a practical cloud-resolving simulation spanning 1.26 years per day.
Notably, the Sunway Oceanlite system also emerged as a climate modeling finalist. In this instance, the system simulated the effects of an underwater volcanic eruption near Tonga in late 2021 and early 2022, encompassing shockwaves, earthquakes, tsunamis, as well as water and ash dispersal. The comprehensive simulation involved a staggering 400 billion particles and ran across 39 million cores within the Oceanlite system, achieving an impressive computational efficiency of 80 percent.
Lastly, the third Gordon Bell climate modeling finalist features a team of researchers in Japan, who harnessed 11,580 nodes within the “Fugaku” supercomputer at RIKEN lab. This team conducted a 1,000 ensemble, 500-meter resolution weather model with a 30-second refresh rate, catering to the 2021 Tokyo Olympics. The scale of their endeavor was truly impressive, comprising over 75,248 weather forecasts distributed over a 30-day period, with each 30-minute forecast taking under three minutes to complete.
Conclusion:
The Oceanlite Supercomputer’s recognition as a Gordon Bell Prize finalist underscores China’s prowess in the field of advanced computing. This achievement reflects the nation’s commitment to pushing the boundaries of computational capability, potentially impacting various industries that rely on high-performance computing solutions. Furthermore, the diverse range of finalists indicates a global race towards harnessing computational power for groundbreaking research and applications, suggesting a vibrant and competitive market for supercomputing technologies.