
TL;DR:
- Video matting is a complex challenge in video production, involving layer separation and composition.
- OmnimatteRF, a novel method, aims to capture dynamic foreground elements and their effects.
- D2NeRF complements OmnimatteRF by handling dynamic and static components in 3D.
- A fusion of 2D foreground layers and a 3D background model forms OmnimatteRF.
- OmnimatteRF demonstrates superior video matting performance across various scenarios.
- Challenges persist in accurately restoring color in shadowed areas.
Main AI News:
In the realm of video production and editing, the art of “video matting” has long been a formidable challenge. It involves the intricate task of dissecting a video into multiple layers, each equipped with its own alpha matte, and then skillfully reassembling these layers to recreate the original video. Over the decades, this process has found numerous applications, from seamless layer swapping to independent layer processing before their final composition. The allure of video matting lies in its potential to selectively isolate the subject of interest, thus facilitating endeavors like rotoscoping in the realm of video production and the subtle backdrop blurring essential for the virtual meetings of today.
Nevertheless, the ambition extends beyond mere subject isolation; it aspires to encapsulate not only the primary subject but also its associated nuances—shadows and reflections—in the video matte. Such a feat would undoubtedly elevate the realism of the final cinematic product while alleviating the laborious endeavor of handcrafting secondary effect segmentations. The prospect of achieving this is tantalizing, and yet, the challenge has remained somewhat underexplored due to the inherent complexity of the problem.
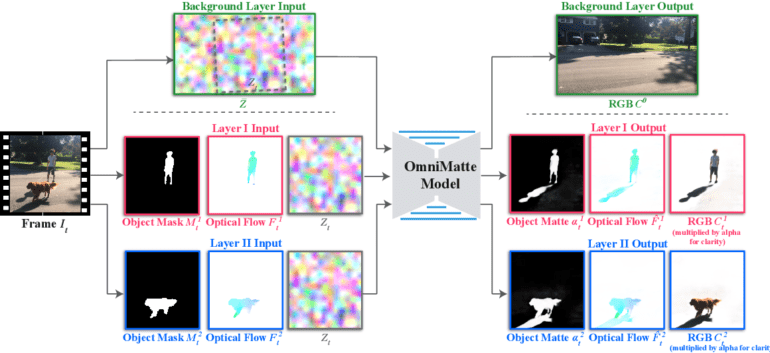
Enter Omnimatte, a pioneering effort that holds promise in tackling this formidable challenge. Omnimattes, embodied as RGBA layers, are designed to faithfully record the dynamic foreground elements and the resulting effects they cast upon the canvas. Employing the power of homography to model backgrounds, Omnimatte is particularly effective in scenarios where the backdrop exhibits a planar nature or when the sole motion involved is rotation.
However, the quest for perfection persists, prompting the emergence of D2NeRF. This cutting-edge solution seeks to dissect the problem by segregating the scene’s dynamic and static components, employing two radiance fields for the purpose. Operating exclusively within the realm of three dimensions, this system exhibits a remarkable capability to handle intricate scenarios featuring significant camera movement. Most notably, D2NeRF operates without the need for external mask inputs, operating in a fully self-supervised manner. Although the integration of 2D guidance elements from video, such as rough masks, remains a challenge, it excels in the segmentation of moving entities from a static background.
Recent research conducted jointly by the University of Maryland and Meta has presented a compelling approach that amalgamates the best of both worlds. It marries the lightweight prowess of 2D foreground layers, capable of representing objects, actions, and effects that prove challenging in a 3D realm, with the versatility of a 3D backdrop model. This synergy extends the scope of video matting, empowering the handling of intricate geometric backgrounds and non-rotational camera movements—a quantum leap beyond the confines of traditional 2D approaches. Termed OmnimatteRF, this technique showcases immense promise.
Empirical validation of OmnimatteRF’s prowess manifests through experimental results, underscoring its remarkable performance across a spectrum of videos. Notably, it dispenses with the need for bespoke parameter adjustments for each video, an efficiency marvel that streamlines the video matting process. Additionally, D2NeRF’s contribution is substantiated by a dataset of five videos meticulously rendered using Kubrics, serving as a benchmark for objective background separation in 3D environments. Furthermore, the team crafted an additional set of five videos rooted in open-source Blender movies, challenging OmnimatteRF with complex animations and dynamic lighting scenarios. Across both datasets, the performance registers as superior, a testament to the strides taken in video matting technology.
Yet, a lingering challenge remains: accurately restoring the color of sections perpetually shrouded in shadows. An animate layer’s alpha channel offers a glimmer of hope, as it holds the potential to record only the additive shadows while preserving the original background color. Alas, the obscurity surrounding this issue in the current context presents a formidable hurdle, begging for a viable resolution.
Conclusion:
OmnimatteRF represents a pivotal advancement in the field of video matting. By seamlessly merging 2D and 3D approaches, it broadens the scope of video editing and promises heightened realism in cinematic productions. This innovation has the potential to reshape the market by streamlining complex editing processes and delivering higher-quality final products. As video production demands continue to grow, OmnimatteRF’s capabilities are poised to meet the evolving needs of the industry.