
TL;DR:
- Advancements in image inpainting for 3D scenes are explored.
- Neural Radiance Fields (NeRFs) enable lifelike 3D transformations from 2D photos.
- Challenges of inpainting in 3D, involving geometry and appearance considerations, are discussed.
- Various approaches, including post hoc solutions and single-reference methods, are examined.
- A new approach is introduced, allowing users to inpaint 3D objects with a textual reference.
- Focus on view-dependent effects (VDEs) and monocular depth estimators enhance inpainting quality.
Main AI News:
In the realm of content creation, the art of image manipulation has evolved into an indispensable tool. Among the many facets of image alteration, the task of inpainting, involving the removal and insertion of objects, has garnered significant attention. Contemporary inpainting models excel at crafting visually seamless alterations within 2D images. Yet, their realm of influence has traditionally been confined to single 2D image inputs. However, a pioneering wave of researchers now seeks to expand the horizons of these models, enabling them to manipulate complete 3D scenes.
The advent of Neural Radiance Fields (NeRFs) has ushered in a new era, facilitating the transformation of ordinary 2D photos into immersive 3D representations. As algorithmic refinements continue to unfold and computational requirements dwindle, these lifelike 3D renderings are poised to become commonplace. Consequently, the research community is embarking on a mission to empower similar manipulations for 3D NeRFs, with a laser focus on inpainting.
Inpainting within the realm of 3D objects presents a constellation of unique challenges. These challenges range from the scarcity of 3D data to the intricate dance between 3D geometry and appearance. The use of NeRFs as a foundational scene representation introduces a layer of complexity. The implicit nature of neural representations renders direct modifications based on geometric understanding unfeasible. Moreover, since NeRFs are trained from images, maintaining coherence across multiple perspectives poses formidable hurdles. The independent inpainting of individual constituent images can give rise to inconsistencies in viewpoints and visually discordant outcomes.
Numerous strategies have been ventured in a bid to confront these challenges head-on. Some approaches endeavor to rectify inconsistencies post hoc, such as the innovative NeRF-In, which amalgamates views through pixel-wise loss, or the perceptive SPIn-NeRF, which deploys a perceptual loss. However, these methodologies may falter when dealing with inpainted views that exhibit pronounced perceptual disparities or complex visual intricacies.
In a contrasting approach, single-reference inpainting methods have emerged, sidestepping view inconsistencies by relying solely on a single inpainted view. Yet, this approach introduces its own set of trials, including diminished visual quality in non-reference views, the absence of view-dependent effects, and challenges associated with disocclusions.
Amidst these formidable limitations, a novel approach has surfaced, poised to revolutionize the world of 3D inpainting.
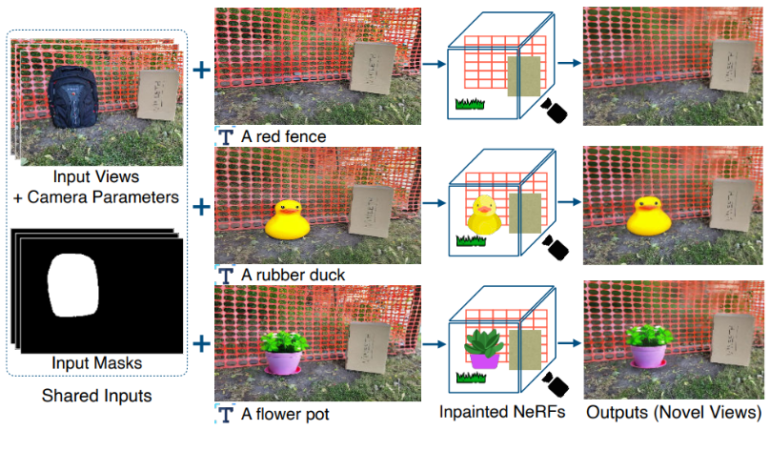
The system’s inputs comprise N images from diverse perspectives, complete with their corresponding camera transformation matrices and masks that delineate undesired regions. Additionally, an inpainted reference view, aligned with the input images, is imperative. This reference serves as the blueprint for what the user envisions in the 3D inpainted scene. The reference can be as straightforward as a textual description of the object intended to replace the mask.
Consider, for instance, the references of “rubber duck” or “flower pot” mentioned earlier. These references can be acquired by employing a single-image text-conditioned inpainter. This innovative approach empowers any user to steer and oversee the generation of 3D scenes with their desired modifications.
An intrinsic focus on view-dependent effects (VDEs) permeates this approach. The authors diligently account for view-dependent alterations, such as specular highlights and non-Lambertian effects, within the scene. To achieve this, they infuse VDEs into the masked regions from non-reference perspectives by harmonizing reference colors with the contextual nuances of other views.
Additionally, the authors introduce monocular depth estimators to shape the geometry of the inpainted region in alignment with the depth of the reference image. Recognizing that not all masked target pixels are visible in the reference, a clever strategy is devised to supervise these occluded pixels through supplementary inpaintings.
Conclusion:
The integration of Neural Radiance Fields (NeRFs) into the realm of 3D inpainting represents a pivotal step forward in image manipulation. This breakthrough approach, which enables users to inpaint 3D scenes based on textual references, not only addresses longstanding challenges but also empowers users to create immersive, customized 3D content. As these innovations mature, they are poised to revolutionize content creation markets by democratizing the creation of complex 3D scenes and driving demand for NeRF-based tools and services.