
TL;DR:
- LLMs, like ChatGPT, have transformed natural language processing.
- LLMs’ computational demands limit practical use.
- OmniQuant is a novel quantization technique addressing LLM efficiency.
- It excels in low-bit quantization, enhancing performance.
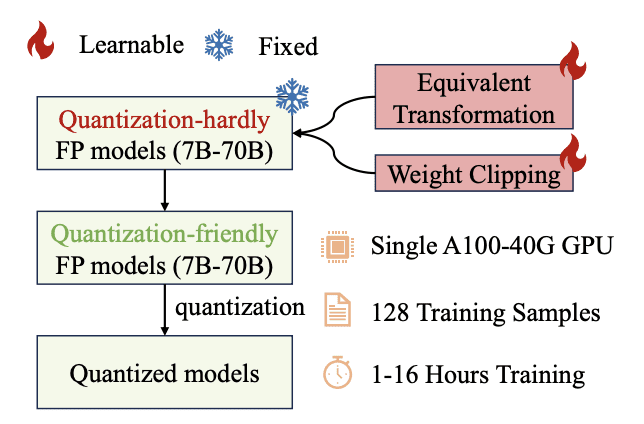
- OmniQuant employs Learnable Weight Clipping (LWC) and Learnable Equivalent Transformation (LET).
- Versatile OmniQuant suits weight-only and weight-activation quantization.
- Implementation is user-friendly, taking just 16 hours on a single GPU.
- OmniQuant maintains performance and outperforms previous PTQ-based methods.
- While still new, OmniQuant promises efficient LLM deployment.
Main AI News:
In the fast-paced world of natural language processing, Large Language Models (LLMs) like ChatGPT have taken center stage. These behemoths have revolutionized how we interact with computers, excelling in tasks ranging from machine translation to text summarization. LLMs have become transformative entities, stretching the limits of natural language understanding and generation. A prime example of this transformation is ChatGPT, a conversational powerhouse born from intensive training on massive text datasets, enabling it to craft text that mirrors human communication.
Yet, there’s a caveat – LLMs are computational and memory hogs. Their sheer size, exemplified by Meta’s LLaMa2 with a staggering 70 billion parameters, poses practical deployment challenges. The question arises: how can we make LLMs leaner without sacrificing their prowess? The answer lies in quantization, a promising technique that trims computational and memory overhead.
Quantization comes in two flavors: post-training quantization (PTQ) and quantization-aware training (QAT). While QAT offers competitive accuracy, it exacts a steep toll in terms of computation and time. Enter PTQ, the go-to choice for many quantization endeavors. It has significantly reduced memory consumption and computational overhead through techniques like weight-only and weight-activation quantization. But here’s the rub – it grapples with low-bit quantization, a linchpin for efficient deployment, due to reliance on handcrafted quantization parameters, yielding suboptimal results.
Let’s introduce you to OmniQuant – a novel quantization technique poised to redefine LLM efficiency. OmniQuant excels in various quantization scenarios, especially in low-bit settings, while preserving the time and data efficiency of PTQ.
OmniQuant takes a distinctive route by preserving the original full-precision weights and weaving in a limited set of learnable quantization parameters. Diverging from the weight optimization intricacies of QAT, OmniQuant’s magic unfolds in a sequential quantization process, layer by layer. This approach invites efficient optimization via straightforward algorithms.
OmniQuant comprises two essential components – Learnable Weight Clipping (LWC) and Learnable Equivalent Transformation (LET). LWC fine-tunes the clipping threshold, tempering extreme weight values, while LET addresses activation outliers by mastering equivalent transformations within a transformer encoder. These components render full-precision weights and activations more receptive to quantization.
OmniQuant’s allure lies in its versatility, catering seamlessly to both weight-only and weight-activation quantization. Even more remarkable is that OmniQuant doesn’t introduce additional computational baggage or parameters for the quantized model; the quantization parameters seamlessly merge into the quantized weights.
Rather than grappling with the daunting task of optimizing all parameters across the LLM simultaneously, OmniQuant takes a stepwise approach, quantifying one layer’s parameters before proceeding to the next. This nimbleness allows OmniQuant to optimize effectively, powered by a simple stochastic gradient descent (SGD) algorithm.
And here’s the icing on the cake – OmniQuant is practical. It’s user-friendly and can be implemented on a single GPU with ease. Training your own LLM is a breeze, taking a mere 16 hours, making it a versatile tool for real-world applications. What’s more, you don’t have to compromise on performance because OmniQuant outperforms previous PTQ-based methods.
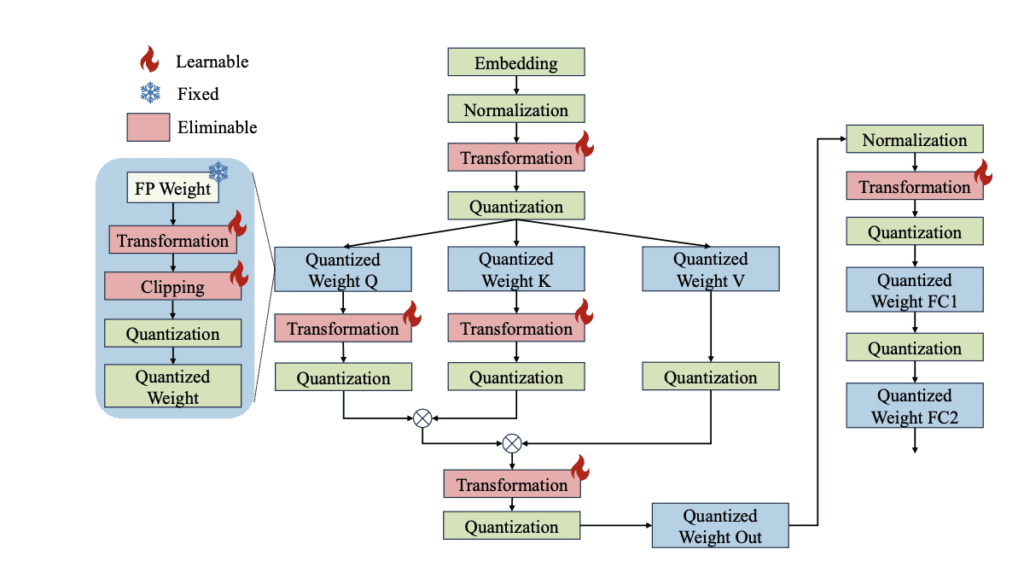
Overview of OmniQuant. Source: Marktechpost Media Inc.
Conclusion:
OmniQuant’s emergence heralds a new era in the market of natural language processing. Its ability to significantly reduce the computational burden of LLMs while maintaining performance levels is a game-changer. This novel quantization technique promises to make LLMs more accessible and practical for a wide range of real-world applications, potentially reshaping the landscape of the NLP market.