
TL;DR:
- Nvidia’s Grace Hopper CPU-GPU superchip shines in MLPerf inference benchmarks.
- Intel’s Habana Labs shows competitive results with Gaudi2 accelerator.
- Google introduces TPU v5e for improved AI accelerator performance.
- Grace Hopper boasts 7× faster C2C link connection and memory-coherent design.
- “Automatic power steering” enhances dynamic performance in Grace Hopper.
- Nvidia also introduced the L4, based on the Ada Lovelace architecture.
- Intel’s CPU Max series enters the LLM inference race.
- Google’s TPUv5e offers a 2.7× improvement in performance per dollar.
Main AI News:
In the ever-evolving landscape of machine learning, the latest MLPerf inference benchmark results have ignited fierce competition among chip manufacturers, server providers, and cloud service giants. These benchmarks shed light on the exceptional performance of cutting-edge hardware, specifically tailored for the recently unveiled 6B-parameter GPT-J, a large language model (LLM) designed to gauge system efficiency in handling LLM workloads, such as Chat-GPT.
Nvidia, a leader in the field, proudly showcased the remarkable capabilities of its Grace Hopper CPU-GPU superchip. Meanwhile, Intel’s Habana Labs demonstrated the prowess of its Gaudi2 accelerator hardware in LLM inference tasks. Adding to the excitement, Google provided a sneak peek into the performance of its newly introduced TPU v5e chip, optimized for LLM workloads.
Grace Hopper, the star of Nvidia’s show, made a spectacular debut in this round. Boasting Nvidia’s 72-Arm Neoverse v2-core CPU, Grace, connected seamlessly to a Hopper H100 die via Nvidia’s proprietary C2C link connection, Grace Hopper left a lasting impression. C2C, celebrated for its remarkable 7× speed boost over PCIe, addresses a historical bottleneck in system performance. What sets Grace Hopper apart from its predecessor, the H100, is its memory-coherent design, enabling direct access to a whopping 480 GB of power-efficient LPDDR5X CPU memory. Notably, this version of GH200 employs HBM3, offering 96 GB of memory, a step up from H100’s 80 GB.
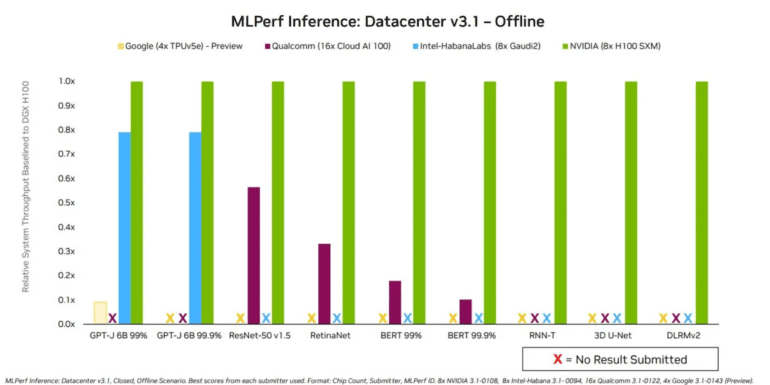
Grace Hopper’s inference scores soared, outperforming the H100 with Intel Xeon systems by a margin ranging from 2% to 17% across various workloads. The most significant advantage was evident in recommendation tasks, while the smallest margin appeared in the new LLM benchmark, where Grace Hopper held a marginal 2% lead in the offline scenario compared to the H100 and Intel Xeon system.
Dave Salvator from Nvidia shared insights, “As LLMs go, it’s a pretty small LLM. Because it doesn’t exceed the 80GB [of HBM] we have on the H100, the performance delta was relatively modest.” Grace Hopper flexed its muscles, achieving a remarkable 10.96 queries per second in server mode and an impressive 13.34 in offline mode for the GPT-J LLM benchmark.
One of the standout features of Grace Hopper is “automatic power steering,” enabling dynamic adjustments in clock frequency based on power availability. Salvator explained, “If the GPU gets very busy, and the CPU is relatively quiet, we can shift the power budget over to the GPU to allow it to offer additional performance.” This adaptive approach optimizes frequency residency throughout the workload, ultimately delivering enhanced performance.
Nvidia didn’t stop at Grace Hopper; they also introduced the L4, based on the Ada Lovelace architecture. This PCIe card, with a GPU thermal design power (TDP) of 72 W and no need for a secondary power connection, is designed to accelerate both graphics and AI workloads, including video analytics. While the L4 exhibited approximately one-tenth the performance of the H100 on LLMs, it significantly improved to around one-fifth of the H100’s scores when handling vision workloads like ResNet.
Intel’s Habana Labs also stepped into the ring with competitive results from its Gaudi2 training accelerator in LLM benchmarking, challenging Nvidia’s Hopper. For GPT-J at 99.0 accuracy, Gaudi2’s scores came within 10% of Grace Hopper’s in the server scenario and 22% in the offline scenario. Gaudi2 boasts 96GB of HBM2e memory, equivalent to Grace Hopper, albeit with the previous generation of HBM, resulting in slightly lower speed and bandwidth. Habana’s strategic choice to deploy Gaudi2, a training chip, allowed it to harness the power of floating-point calculations for LLM inference.
Intel also joined the LLM inference race, submitting results for its CPUs. Dual Intel Xeon Platinum 8480+ (Sapphire Rapids) managed to infer 2.05 queries per second in offline mode, while dual Intel CPU Max (Sapphire Rapids with 64 GB of HBM2e) CPUs achieved 1.3 queries per second.
Jordan Plawner from Intel expressed, “This was the first submission for the Intel CPU Max series on BF16, and the team is continuing to optimize the AI software driver. For future submissions, we expect that our Intel Xeon CPU Max series performance will demonstrate the full value of high-bandwidth memory in package across BF16 and 8-bit.”
Google, not one to be left behind, provided a tantalizing glimpse into its latest AI accelerator silicon, the TPUv5e. Designed to deliver improved performance per dollar compared to the TPUv4, the TPUv5e is already available in Google’s cloud, with configurations supporting up to 256-chip pods. Each chip packs a punch with 393 TOPS at INT8, and the pod utilizes Google’s proprietary inter-chip interconnect (ICI).
Four TPUv5es showcased their capabilities, achieving 9.81 offline samples per second compared to 13.07 for a single Nvidia H100. Normalizing for per-accelerator performance places H100’s performance at approximately 5×.
Google’s calculations indicate a staggering 2.7× improvement in performance per dollar for TPUv5e compared to the previous generation. This enhancement is attributed to an optimized inference software stack, incorporating DeepMind’s SAX and Google’s XLA compiler, alongside innovations in transformer operator fusion and post-training weight quantization to INT8, as well as sharding strategies and other refinements. As the race for AI supremacy continues, these benchmark results mark significant progress in the world of machine learning and artificial intelligence.
Conclusion:
The AI hardware landscape is rapidly evolving, with Nvidia’s Grace Hopper making a strong statement in MLPerf inference benchmarks. This not only signifies Nvidia’s dominance in the AI hardware market but also highlights the intense competition among chip manufacturers, promising advancements that will benefit the broader market with more powerful and cost-effective AI solutions.