
TL;DR:
- Some universities are refraining from using Turnitin’s AI software designed to detect AI-written text in student essays.
- Turnitin’s tool assigns scores to sentences and documents, identifying AI influence, but universities fear false accusations.
- Notably, Vanderbilt University argues even a minimal false positive rate is too high, potentially flagging 750 papers annually.
- Critics emphasize the lack of transparency in Turnitin’s AI detection methods and privacy concerns.
- Turnitin stresses that its AI tool should aid educators, not replace their judgment, and is automatically enabled for users.
- The incident at the University of Texas A&M-Commerce highlights the significant impact of AI detection results on educators’ decisions.
- Distinguishing between human and AI-authored text remains a complex challenge in AI content detection.
Main AI News:
In recent times, a controversial debate has emerged within the hallowed halls of academia, where some universities are choosing to forego the utilization of Turnitin’s AI-powered software designed to detect AI-generated text in student essays and assignments. Turnitin, renowned for its role in identifying plagiarism, expanded its repertoire in April to encompass machine-written prose.
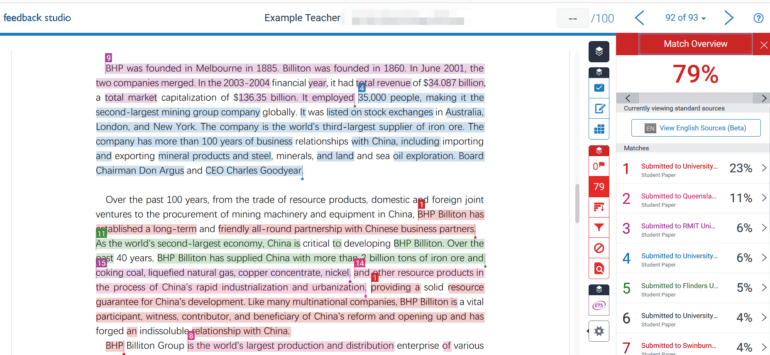
This cutting-edge software, when enabled, rigorously scrutinizes documents, dissects the text into digestible segments, and meticulously evaluates each sentence. It then assigns a score: 0 if it appears to be the handiwork of human minds or 1 if it bears the indelible imprint of AI-driven composition. An average score is tabulated for each document, offering a prediction on the extent to which AI may have contributed to the text.
While Turnitin staunchly maintains that its AI text detection tool is not without flaws, asserting a false positive rate of less than one percent, several prominent American universities remain unconvinced. Vanderbilt, Michigan State, Northwestern, and the University of Texas at Austin have chosen to abstain from employing this software, citing concerns over potential misidentifications and their adverse consequences, as reported by Bloomberg.
Vanderbilt University, in particular, argues that even this minimal false positive rate is unacceptably high. It estimates that adopting the technology could lead to the erroneous flagging of 750 papers each year, a significant number given the 75,000 papers processed through Turnitin’s system in 2022.
Moreover, there exists a broader question regarding the very efficacy of Turnitin’s method in detecting AI-generated writing. Critics argue that the lack of transparency in revealing the specific patterns and criteria used for this determination raises legitimate concerns. Michael Coley, an instructional technology consultant at Vanderbilt, articulates these concerns, emphasizing the need to address privacy issues associated with funneling student data into a detector managed by an external entity with ambiguous privacy and data usage policies.
Coley further underscores the intrinsic complexities of AI detection, particularly as AI tools evolve and proliferate. He posits a fundamental skepticism about the feasibility of effective AI detection software, asserting that it may not be a viable solution.
Annie Chechitelli, Turnitin’s chief product officer, contends that the AI-flagging tool should not be wielded as an automatic punitive measure. She notes that 98 percent of Turnitin’s customers are utilizing the feature, albeit it is automatically enabled, and educators who wish to bypass its scores must explicitly opt out or simply ignore them.
At the heart of Turnitin’s philosophy is the belief that no technology can supplant the nuanced understanding an educator possesses about their students, their writing style, and their educational backgrounds. Chechitelli emphasizes that Turnitin’s technology is intended to augment educators’ discretion by providing data points and resources to facilitate meaningful conversations with students, rather than serving as a definitive determinant of misconduct.
Nonetheless, despite the software’s intended purpose, the results it yields wield considerable influence over educators’ judgments. A recent incident at the University of Texas A&M-Commerce exemplifies this, where a lecturer used ChatGPT to discern whether student papers were machine-generated or not, resulting in withheld grades and a flurry of academic uncertainty.
In the realm of AI-generated content detection, distinguishing between human and machine-authored text remains a formidable challenge. OpenAI’s AI-output classifier, for instance, was withdrawn due to its lackluster accuracy, prompting a quest for more effective detection methodologies. Adding complexity to the issue, AI detection software can falter when analyzing text that has been human-edited and AI-enhanced, or vice versa. A study led by computer scientists at the University of Maryland revealed that even the best classifiers struggled to differentiate AI-generated text, akin to a coin toss in terms of accuracy.
The debate surrounding Turnitin’s AI text detection tool rages on, a testament to the intricate interplay between technology and academia, and the inherent complexities of identifying the fingerprints of artificial intelligence in the realm of written expression.
Conclusion:
The controversy surrounding Turnitin’s AI text detection tool underscores the delicate balance between technology and academia. While AI has the potential to augment plagiarism detection, it also raises significant concerns about accuracy, transparency, and privacy. Educational institutions must carefully consider the implications of adopting such tools while recognizing the continued complexity of distinguishing between human and AI-authored content in academic settings. This controversy highlights the evolving landscape of AI’s role in education and the need for robust safeguards and transparent practices.