
TL;DR:
- “FreeMan” dataset addresses the limitations of existing 3D human pose estimation datasets.
- Comprises 11 million frames from 8,000 sequences, captured across diverse scenarios.
- Encompasses 40 subjects in 10 different scenes, both indoor and outdoor.
- Introduces variability in camera parameters and human body scales for real-world relevance.
- Automated annotation pipeline enhances precision for 3D annotations.
- Valuable for tasks like monocular 3D estimation, 2D-to-3D lifting, multi-view 3D estimation, and neural rendering.
- Outperforms existing datasets, demonstrating superior generalizability in real-world scenarios.
- Improves model performance with larger-scale training in 2D-to-3D pose lifting experiments.
Main AI News:
In the realm of artificial intelligence, graphics, and human-robot interaction, the quest to estimate the 3D structure of the human body from real-world scenes has been a formidable challenge. However, existing datasets for 3D human pose estimation have often fallen short, as they are typically gathered under controlled conditions with static backgrounds, failing to encompass the rich tapestry of real-world scenarios. This deficiency has, in turn, impeded the development of precise models applicable to real-world contexts.
Prominent datasets such as Human3.6M and HuMMan, while valuable in their own right, are predominantly confined to controlled laboratory settings. They lack the diversity, complexity, and scalability inherent to real-world environments, ultimately constraining their efficacy when employed in such contexts. Although researchers have proffered numerous models for 3D human pose estimation, their performance often falters in the face of real-world challenges due to the inadequacies of existing datasets.
Enter the innovative “FreeMan” dataset, introduced by a team of researchers hailing from China. This groundbreaking creation is poised to revolutionize the field of 3D human pose estimation in real-world scenarios. “FreeMan” emerges as a substantial contribution, designed explicitly to surmount the limitations that have plagued existing datasets, thus fostering the development of more precise and robust models for this pivotal task.
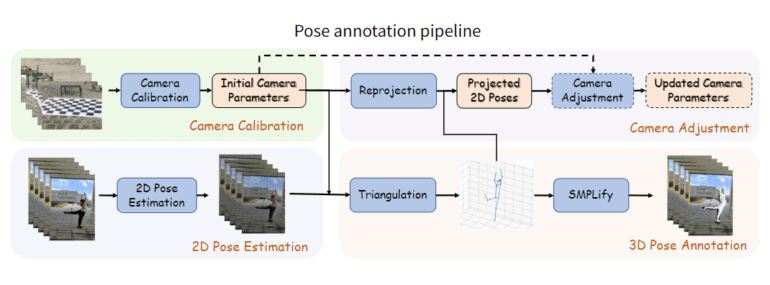
“FreeMan” stands as a comprehensive dataset comprising a staggering 11 million frames, harvested from 8,000 sequences, all captured through the lens of 8 synchronized smartphones across a diverse range of scenarios. Encompassing 40 subjects amidst 10 distinct scenes—spanning both indoor and outdoor settings, complete with varying lighting conditions—this dataset ushers in vital variability in camera parameters and human body scales, rendering it a more faithful reflection of real-world intricacies. The research group has meticulously crafted an automated annotation pipeline to birth this dataset, a pipeline that deftly engenders precise 3D annotations through the intricate dance of human detection, 2D keypoint detection, 3D pose estimation, and mesh annotation. The resulting dataset emerges as a prized asset, boasting applicability across multiple fronts, from monocular 3D estimation and 2D-to-3D lifting to multi-view 3D estimation and neural rendering of human subjects.
The researchers behind “FreeMan” have gone the extra mile by furnishing comprehensive evaluation baselines for various tasks, rigorously comparing models trained on this dataset with their counterparts trained on existing datasets such as Human3.6M and HuMMan. Impressively, models honed through “FreeMan” showcased markedly superior performance when put to the test against the 3DPW dataset, firmly establishing the dataset’s unmatched adaptability to real-world scenarios.
In the realm of multi-view 3D human pose estimation, models trained on “FreeMan” exhibited an enhanced ability to generalize compared to their counterparts trained on Human3.6M, especially when facing cross-domain datasets. The results spoke volumes about the merits of “FreeMan’s” diversity and scale.
Nonetheless, “FreeMan” did not shy away from presenting challenges, particularly in 2D-to-3D pose lifting experiments, where models trained on this dataset confronted greater difficulty levels than their peers trained on alternative datasets. Yet, the narrative took a turn for the positive when models underwent training on the entire expanse of “FreeMan.” Here, a discernible improvement in performance emerged, underscoring the dataset’s latent potential to elevate model competence through expansive training.
In summation, the “FreeMan” dataset emerges as a trailblazing force in the arena of 3D human pose estimation within real-world contexts. It successfully addresses an array of limitations ingrained in existing datasets by ushering in diversity across scenes, human actions, camera parameters, and human body scales. Backed by a sophisticated automated annotation pipeline and a colossal data reservoir, “FreeMan” has etched its name as an invaluable asset in the pursuit of more precise and resilient algorithms for 3D human pose estimation. The research paper illuminates “FreeMan’s” extraordinary aptitude for generalization, positioning it as a catalyst for progress in human modeling, computer vision, and human-robot interaction—a bridge spanning the chasm between controlled lab settings and the multifaceted realities of the world.
Conclusion:
The introduction of the “FreeMan” dataset heralds a pivotal advancement in the field of 3D human pose estimation. Its ability to surmount the limitations of existing datasets and offer diverse, real-world scenarios opens new doors for the market. This dataset holds immense potential to catalyze advancements in human modeling, computer vision, and human-robot interaction, forging a path toward more accurate and robust algorithms that bridge the gap between controlled environments and the complexities of real-world applications. Businesses and researchers alike should keenly monitor and leverage this development for enhanced innovation and practical applications in AI and related domains.