
TL;DR:
- KOSMOS-2.5 is a cutting-edge multimodal model designed to handle two key transcription tasks: spatially-aware text block generation and markdown text output from images.
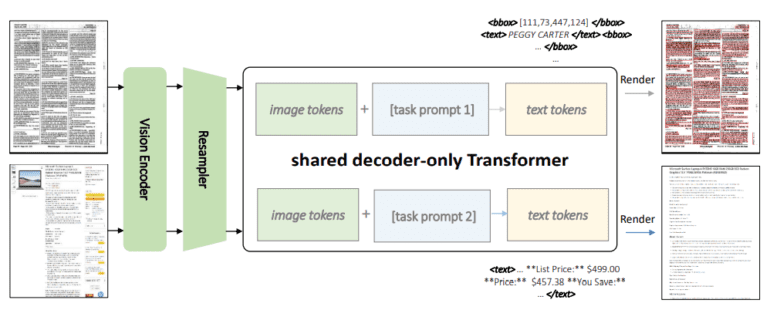
- It employs a shared Transformer architecture, merging a Vision Transformer (ViT) vision encoder with a Transformer-based language decoder via a resampler module.
- The model’s training involves a vast dataset of text-heavy images, enhancing its multimodal literacy.
- Experimental results highlight KOSMOS-2.5’s exceptional performance in text recognition and generation from images, especially in few-shot and zero-shot learning scenarios.
- Challenges remain, notably in fine-grained control of document elements’ positioning using natural language instructions.
- The market implications include a potential breakthrough in image-based text analysis, opening doors to diverse real-world applications.
Main AI News:
In the realm of artificial intelligence, large language models (LLMs) have reigned supreme in recent years, but their dominion has predominantly been in the domain of textual comprehension. The intricacies of grasping visual content have remained an elusive challenge. Enter the Multimodal Large Language Models (MLLMs), a paradigm-shifting innovation bridging this chasm. These MLLMs amalgamate textual and visual data within a singular Transformer-based model, ushering in a new era of AI prowess.
Kosmos-2.5: A Unified Vision for Text and Images
KOSMOS-2.5 represents a watershed moment in the evolution of MLLMs, adeptly addressing two intricately linked transcription tasks within an integrated framework. The inaugural task entails the generation of textual blocks infused with spatial intelligence, accompanied by the precise allocation of spatial coordinates to text lines residing within text-enriched images. The secondary task revolves around the production of meticulously structured text in markdown format, capable of capturing a spectrum of styles and arrangements.
These twin objectives find a harmonious convergence within a single system, ingeniously employing a shared Transformer architecture, task-specific prompts, and adaptive text representations. The architectural blueprint of KOSMOS-2.5 harmoniously melds a vision encoder, drawing inspiration from the Vision Transformer (ViT), with a linguistic decoder founded upon the Transformer architecture. The fusion is achieved seamlessly through the intermediary resampler module.
Training the Multimodal Maestro
The journey towards crafting KOSMOS-2.5 entails an intensive pretraining phase, wherein the model imbibes knowledge from a substantial trove of text-centric images. These images encompass text lines meticulously encompassed by bounding boxes, along with pristine markdown text. This dual-task training regimen imbues KOSMOS-2.5 with a holistic, multimodal literacy, elevating its capabilities to uncharted heights.
The Grand Unveiling
Behold the architectural marvel of KOSMOS-2.5, as depicted above. This technological marvel isn’t merely an academic pursuit; it’s a powerhouse in the real world. Its mettle has been rigorously evaluated across two pivotal domains: seamless end-to-end document-level text recognition and the nimble generation of text from images, elegantly rendered in markdown format. Experimental verdicts resoundingly testify to its prowess in deciphering text-intensive image-based tasks. Beyond this, KOSMOS-2.5 unfurls its potential in realms demanding few-shot and zero-shot learning, cementing its status as a versatile instrument for real-world applications grappling with text-drenched images.
Towards New Horizons
Despite these remarkable feats, KOSMOS-2.5 does not come devoid of challenges. While it has demonstrated its prowess in handling spatial coordinates, it currently lacks the finesse to interpret natural language instructions for precise control of document elements’ positioning—a fertile ground for future exploration. Furthermore, the journey ahead beckons toward the horizon of model scaling, a terrain ripe for expansion and advancement within the broader research landscape. KOSMOS-2.5, with its groundbreaking capabilities, is poised to spearhead this charge into uncharted territory.
Conclusion:
The introduction of KOSMOS-2.5 marks a significant leap in AI capabilities, bridging the gap between text and visual content processing. This innovation opens up new horizons for businesses and industries, enabling them to harness the power of AI in understanding and generating content from text-intensive images. As the technology matures and addresses its current limitations, we can anticipate a wave of transformative applications across various market sectors, from document processing to content generation and beyond. Businesses that embrace KOSMOS-2.5 and similar advancements stand to gain a competitive edge in the evolving AI landscape.