
TL;DR:
- Tsinghua University introduces OpenChat, a groundbreaking framework for enhancing open-source language models.
- OpenChat leverages mixed-quality data, distinguishing between expert-generated and suboptimal data.
- It employs Conditioned Reinforcement Learning Fine-Tuning (C-RLFT) to streamline training and reduce reliance on complex reward models.
- OpenChat’s open chat-13 b model outperforms other 13-billion parameter models in instruction-following tasks.
- The research underscores the importance of high-quality training data and paves the way for simplified language model training.
Main AI News:
In the ever-evolving landscape of natural language processing, the prowess of large language models has witnessed an exponential surge. Researchers and global organizations have been tirelessly striving to push the envelope, seeking to enhance the performance of these models across various natural language understanding and generation tasks. One paramount facet of this advancement revolves around the caliber of the training data these models are nurtured on. In this article, we embark on a voyage through a groundbreaking research paper that tackles the formidable challenge of fortifying open-source language models by harnessing mixed-quality data. Join us as we delve into the innovative methodology, technology, and far-reaching implications for the realm of natural language processing.
Mixed-quality data, comprising both expert-generated and suboptimal data, constitutes a formidable obstacle in the training of language models. Expert data, meticulously crafted by state-of-the-art models such as GPT-4, typically epitomizes the pinnacle of quality, serving as the gold standard for training. Conversely, suboptimal data stemming from older models like GPT-3.5 may exhibit a lower quality quotient, thereby presenting a formidable hurdle during the training process. The research under scrutiny here duly acknowledges this dichotomy of mixed-quality data and strives to bolster the instruction-following prowess of open-source language models.
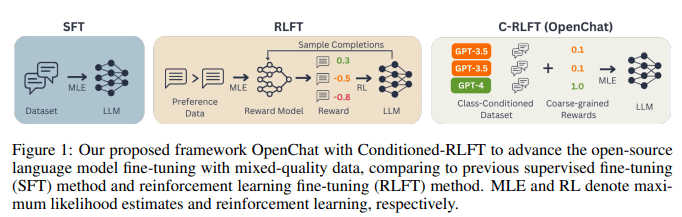
Before we plunge into the crux of the proposed methodology, let us briefly peruse the contemporary methods and tools employed in language model training. One widely embraced approach in augmenting these models is Supervised Fine-Tuning (SFT). Within the realm of SFT, models undergo rigorous training on instruction-following tasks by leveraging high-quality, expert-generated data, thus providing a guiding light toward generating accurate responses. Additionally, the domain of Reinforcement Learning Fine-Tuning (RLFT) has witnessed a surge in popularity. RLFT entails the solicitation of preference feedback from human users, subsequently training the models to maximize rewards contingent upon these preferences.
In a groundbreaking revelation, Tsinghua University introduces the OpenChat paradigm through its seminal research. OpenChat is an avant-garde framework that elevates open-source language models by harnessing mixed-quality data. At its nucleus resides the Conditioned Reinforcement Learning Fine-Tuning (C-RLFT), an innovative training approach that streamlines the training regimen and mitigates the dependence on intricate reward models.
C-RLFT imbues language models with enriched input data, meticulously segregating data sources based on their quality. This segmentation is meticulously executed through the implementation of a class-conditioned policy, enabling the model to effectively differentiate between expert-crafted data of the highest quality and suboptimal data of diminished quality. In doing so, C-RLFT furnishes explicit cues to the model, empowering it to augment its instruction-following capabilities significantly.
The performance evaluation of OpenChat, particularly the open chat-13 b model, has been conducted across a multitude of benchmarks. One noteworthy benchmark employed is AlpacaEval, which rigorously scrutinizes the model’s ability to adhere to instructions. Openchat-13b astoundingly outperforms other 13-billion parameter open-source models, such as LLaMA-2, manifesting higher success rates and superior performance across instruction-following tasks, thereby underlining the efficacy of the C-RLFT approach.
The research team underscores the paramount importance of data quality in this groundbreaking endeavor. Despite its limited quantity, expert-generated data plays an instrumental role in elevating the efficacy of language models. The capacity to discern between expert and suboptimal data, coupled with the C-RLFT technique, begets substantial enhancements in model performance. This revelation emphatically accentuates the significance of meticulously curated, high-quality training data as the bedrock for the triumphant training of language models.
Conclusion:
OpenChat’s innovative approach, centered around C-RLFT and mixed-quality data, signifies a significant leap forward in natural language processing. This breakthrough simplifies training while improving model performance, making it more accessible for diverse applications. It underscores the importance of data quality and opens new avenues for research and development in the AI market, potentially revolutionizing the industry’s landscape.