
TL;DR:
- LLM-Grounder introduces an innovative approach to 3D visual grounding for domestic robots.
- Large Language Models (LLMs) like ChatGPT and GPT-4 play a pivotal role in understanding complex language queries.
- LLM-Grounder breaks down language into semantic concepts and leverages spatial and commonsense knowledge.
- It employs an open vocabulary and zero-shot learning, eliminating the need for labeled data.
- Experimental evaluations show superior performance in zero-shot grounding accuracy, outperforming existing methods.
- LLM-Grounder promises significant advancements in robotics applications.
Main AI News:
Understanding three-dimensional environments is paramount for domestic robots, enabling them to excel in navigation, manipulation, and responding to complex queries. However, existing methods often struggle with intricate language queries and rely heavily on extensive labeled datasets.
Meet the Pioneers: ChatGPT and GPT-4
Enter the realm of Large Language Models (LLMs), exemplified by ChatGPT and GPT-4, which boast remarkable language comprehension abilities, encompassing planning and tool utilization. These LLMs break down formidable challenges into manageable components, mastering the art of employing tools to accomplish sub-tasks efficiently. Their arsenal includes parsing complex language into semantic elements, seamlessly engaging with tools and surroundings to gather feedback, and employing spatial and commonsense knowledge to anchor language to specific objects – a prerequisite for tackling 3D visual grounding challenges.
Introducing LLM-Grounder: A Paradigm Shift
Nikhil Madaan and a team of researchers from the University of Michigan and New York University proudly present LLM-Grounder, a groundbreaking zero-shot LLM-agent-based 3D visual grounding paradigm with an open vocabulary. While conventional visual grounding excels at grounding basic noun phrases, LLM-Grounder boldly addresses the limitations inherent in “bag-of-words” approaches by embracing the complexities of language deconstruction, spatial reasoning, and commonsense comprehension.
The LLM-Powered Grounding Process
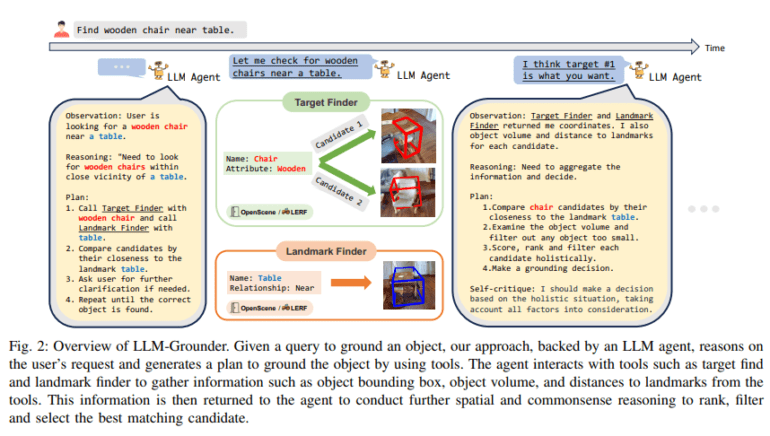
LLM-Grounder harnesses the prowess of LLMs to orchestrate the grounding process. Upon receiving a natural language query, the LLM dissects it into constituent parts or semantic concepts, encompassing the desired object’s type, properties (including color, shape, and material), landmarks, and spatial relationships. These sub-queries are then dispatched to a visual grounding tool, supported by OpenScene or LERF, both of which represent CLIP-based open-vocabulary 3D visual grounding methodologies.
Elevating Spatial Understanding
The visual grounding tool suggests potential bounding boxes within the scene, marking the most promising candidates corresponding to the query. These tools also calculate crucial spatial information, such as object volumes and distances to landmarks, which is relayed back to the LLM agent. Armed with this data, the LLM agent performs a comprehensive assessment, considering spatial relations and commonsense, ultimately selecting the candidate that aligns best with the original query’s criteria. This iterative process continues until a decision is reached, distinguishing LLM-Grounder from existing neural-symbolic approaches by leveraging contextual cues.
Zero-Shot Brilliance
Remarkably, LLM-Grounder stands out as it requires no labeled data for training. Given the diverse semantics of 3D environments and the scarcity of 3D-text labeled data, its open-vocabulary and zero-shot adaptability to novel 3D scenarios and arbitrary text queries are compelling features.
Performance Beyond Expectations
The researchers conducted rigorous evaluations of LLM-Grounder using the ScanRefer benchmark, assessing its ability to interpret compositional visual referential expressions—a critical metric in 3D vision language. The results are nothing short of impressive, showcasing LLM-Grounder’s supremacy in zero-shot grounding accuracy on ScanRefer without the crutch of labeled data. Furthermore, it enhances the grounding capabilities of open-vocabulary methods like OpenScene and LERF. Notably, LLM’s efficacy scales in proportion to the query’s complexity, affirming the method’s efficiency in addressing 3D vision language challenges. Its implications are profound, particularly in the realm of robotics, where adaptability and rapid response to evolving queries are paramount.
Conclusion:
LLM-Grounder’s emergence signifies a transformative leap in 3D visual grounding, offering robots the ability to navigate, manipulate, and respond to queries with unprecedented efficiency. This breakthrough has far-reaching implications for the robotics market, paving the way for more adaptable and context-aware household robots, thereby expanding their utility and market potential.