
TL;DR:
- Columbia University introduces Zero-1-to-3 AI framework for altering camera viewpoints from single RGB images.
- Addresses challenges in augmented reality, robotics, and art restoration.
- Utilizes deep learning and synthetic data for robust viewpoint manipulation.
- Excels in 3D reconstruction and novel view synthesis.
- Overcomes limitations of large-scale generative models.
- Offers groundbreaking solutions for computer vision.
Main AI News:
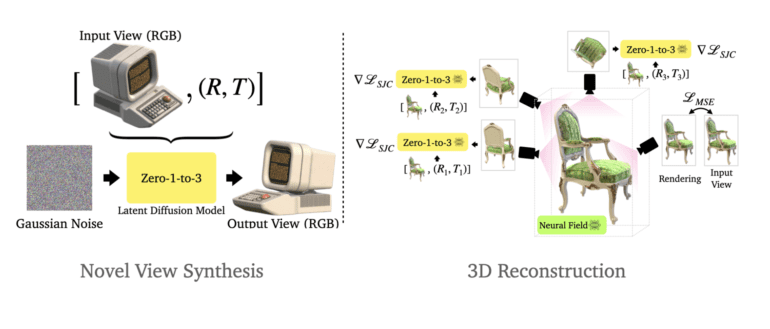
In the dynamic realm of computer vision, a formidable challenge has confounded researchers for years: the ability to manipulate the camera perspective of an object using just a solitary RGB image. This intricate puzzle holds vast significance in domains such as augmented reality, robotics, and the restoration of artistic masterpieces. Prior attempts, relying on handcrafted features and geometric assumptions, fell short in delivering practical solutions. However, a groundbreaking solution has emerged from the labs of Columbia University – the pioneering Zero-1-to-3 framework. Harnessing the power of deep learning and expansive diffusion models, this framework draws upon learned geometric insights from synthetic data to seamlessly manipulate camera viewpoints, even extending its prowess to unconventional scenarios like the restoration of impressionist paintings. Notably, it also excels in 3D reconstruction from a single image, surpassing state-of-the-art models.
In the ever-evolving landscape of 3D generative models and single-view object reconstruction, recent leaps forward owe their success to advancements in generative image architectures and the availability of vast image-text datasets. These strides have unlocked the ability to synthesize intricate scenes and objects using diffusion models, celebrated for their scalability and efficiency in image generation. Traditionally, transitioning these models into the 3D realm required copious labeled 3D data, a resource-intensive undertaking. However, recent innovations have bypassed this need by transferring pre-trained large-scale 2D diffusion models into the 3D domain, effectively circumventing the demand for ground truth 3D data.
Enter the Zero-1-to-3 framework, a groundbreaking solution to the challenge of altering an object’s camera perspective using just a single RGB image. At its core lies a conditional diffusion model, meticulously trained on synthetic data, endowing it with the ability to decipher the intricacies governing relative camera viewpoints. With this newfound capability, the framework can produce novel images that faithfully replicate the desired camera transformations. Impressively, the model exhibits robust zero-shot generalization capabilities, effortlessly extending its expertise to previously unencountered datasets and real-world images. Moreover, the framework’s utility extends into the domain of 3D reconstruction from a solitary image, where it outperforms contemporary models, marking a significant stride forward in single-view 3D reconstruction and novel view synthesis.
Yet, the inherent limitations of large-scale generative models persist, including the lack of explicit encoding of viewpoint correspondences and the influence of viewpoint biases sourced from the vast expanse of the internet. Nevertheless, these challenges have met their match in innovative solutions and methodologies, propelling the Zero-1-to-3 framework to the forefront of computer vision advancements.
This method heralds a paradigm shift in the art of manipulating camera viewpoints with just a single RGB image. Not only does it outshine contemporary models in single-view 3D reconstruction and novel view synthesis, but it also boasts the creation of highly photorealistic images that closely mirror ground truth. This method excels in generating high-fidelity viewpoints while preserving object characteristics, identity, and intricate details. Furthermore, it distinguishes itself by producing a diverse array of plausible images from novel vantage points, effectively encapsulating the inherent uncertainty of the task.
Conclusion:
Columbia University’s Zero-1-to-3 AI framework represents a game-changing advancement in computer vision. Its ability to manipulate camera viewpoints from single RGB images has wide-ranging applications in industries like augmented reality, robotics, and art restoration. This innovation, driven by deep learning and synthetic data, not only excels in 3D reconstruction and novel view synthesis but also overcomes the limitations of existing generative models. For the market, this signifies a leap forward in the capabilities of computer vision systems, offering unprecedented opportunities for businesses to enhance their products and services in various domains.