
TL;DR:
- Databricks introduces GPU and LLM optimization support for Model Serving on the Lakehouse Platform.
- Automatic LLM optimization eliminates the need for manual configuration.
- Databricks Model Serving is the first serverless GPU serving product integrated into a unified data and AI platform.
- Simplified AI model deployment, suitable for users with varying levels of infrastructure expertise.
- Support for diverse models, including natural language, vision, audio, tabular, and custom models.
- Streamlined deployment through MLflow integration.
- Fully managed service adjusts instance scaling for cost savings and performance optimization.
- Optimized LLM Serving results in a remarkable 3-5x reduction in latency and cost.
- Databricks Model Serving supports MPT and Llama2 models with plans for more in the future.
Main AI News:
Databricks has unveiled its latest innovation: the public preview of GPU and LLM optimization support for Databricks Model Serving. This transformative feature empowers users to effortlessly deploy a diverse array of AI models, including LLMs and Vision models, directly onto the Lakehouse Platform.
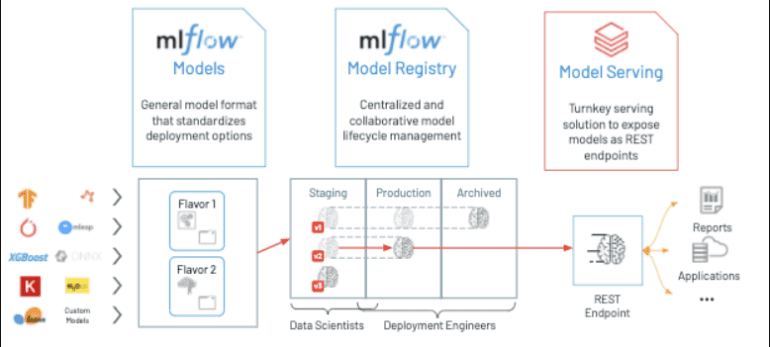
Databricks Model Serving heralds a new era of AI deployment by offering automatic optimization for LLM Serving. This means achieving top-tier performance without the burdensome task of manual configuration. What sets this product apart is its distinction as the first serverless GPU serving solution integrated into a unified data and AI platform. This all-encompassing platform facilitates the seamless creation and deployment of GenAI applications, covering the entire spectrum from data ingestion to model deployment and ongoing monitoring.
One of the standout features of Databricks Model Serving is its ability to simplify the deployment of AI models, making it accessible even to individuals lacking extensive infrastructure expertise. With this service, users can effortlessly deploy a wide variety of models, whether they are focused on natural language, vision, audio, tabular data, or custom models. Importantly, it doesn’t matter how these models were trained—whether from the ground up, using open-source resources, or fine-tuned with proprietary data. The process is straightforward: log your model with MLflow, and Databricks Model Serving takes the reins. It automatically prepares a production-ready container, complete with GPU libraries like CUDA, and deploys it to serverless GPUs. This fully managed service handles all aspects of management, ensuring version compatibility and even patching, while seamlessly adjusting instance scaling to match traffic patterns. This level of automation not only optimizes performance and latency but also translates into significant cost savings by right-sizing infrastructure resources.
Furthermore, Databricks Model Serving has introduced specialized optimizations for efficiently serving large language models (LLM), resulting in a remarkable 3-5x reduction in latency and cost. The beauty of Optimized LLM Serving is its simplicity. Users need only provide the model and its weights, and Databricks takes care of the rest, ensuring that your model operates at peak efficiency. This streamlined approach frees you to concentrate on the vital task of integrating LLM into your application without the complexities of low-level model optimization. Currently, Databricks Model Serving automatically optimizes MPT and Llama2 models, with ambitious plans to extend support for additional models in the near future.
Conclusion:
Databricks’ introduction of GPU and LLM optimization support for Model Serving marks a significant leap in the AI deployment landscape. This innovative offering not only streamlines the deployment of diverse AI models but also automates optimization, reduces costs, and enhances performance. Databricks continues to shape the market by providing a comprehensive solution that empowers organizations to harness the full potential of AI with ease and efficiency.