
TL;DR:
- Computer Vision’s significance grows with AI’s expansion.
- Semantic segmentation, a crucial task, traditionally relies on supervised learning with labeled data.
- DepthG, introduced by researchers from Ulm University and TU Vienna, integrates depth maps into unsupervised semantic segmentation.
- DepthG focuses on learning depth-feature correlations and efficient feature selection using 3D sampling.
- It doesn’t require depth maps during inference, making it adaptable to various scenarios.
- DepthG shows potential for cost-effective and advanced computer vision applications.
Main AI News:
In the realm of Artificial Intelligence, Computer Vision stands as one of the most influential subfields, driven by the exponential growth of AI itself. As AI continues to evolve and expand its horizons, Computer Vision marches forward, harnessing its remarkable capabilities. Among the pivotal tasks within this domain, semantic segmentation emerges as a critical endeavor, involving the meticulous assignment of object or region classes to individual pixels within an image. Industries spanning from autonomous driving and retail to face recognition leverage this technique for myriad applications.
Traditionally, the realm of semantic segmentation relied heavily on supervised learning, demanding copious volumes of labeled data for effective training. Yet, the acquisition and annotation of such extensive datasets have proven to be time-consuming and resource-intensive endeavors. Moreover, the training of neural networks for semantic segmentation has incurred substantial costs, primarily due to the necessity of human-made annotations, wherein each pixel within an image is painstakingly labeled according to its corresponding object or region class.
However, in recent times, unsupervised learning has emerged as a formidable contender, challenging the supremacy of supervised methods and approaching their performance levels. The primary objective of unsupervised semantic segmentation is to extract semantic insights from datasets by uncovering correlations among randomly selected image feature values. In a groundbreaking research initiative, a collaborative team hailing from Ulm University and TU Vienna has elevated these advances by introducing a novel dimension into the training process – the integration of depth information.
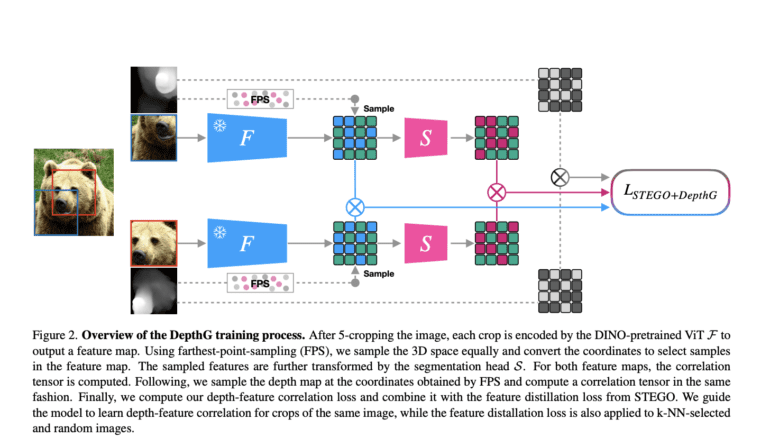
This revolutionary approach, aptly named DepthG, aims to infuse spatial context, specifically depth maps, into the training process of STEGO, a noteworthy model employing a Vision Transformer (ViT) to extract features from images. STEGO then employs a contrastive learning approach to distill these features across the dataset. Notably, while STEGO operates solely within the pixel space, disregarding the scene’s spatial layout, this pioneering development seamlessly integrates depth maps into STEGO’s training regimen.
The research unfolds through two pivotal contributions, as follows:
- Learning Depth-Feature Correlations: This facet centers on fostering a profound understanding of the interplay between depth information and visual feature correlations. By spatially connecting depth maps and feature maps derived from images, the neural network gains a deeper comprehension of the fundamental arrangement of the scene in three dimensions.
- Efficient Feature Selection with 3D Sampling: Here, the emphasis lies in enhancing the selection of pertinent characteristics for segmentation. This is achieved through the application of Farthest-Point Sampling, a method that harnesses 3D sampling techniques on the scene’s depth data. It strategically chooses characteristics distributed in 3D space, rendering the scene’s structure more discernible.
A distinctive hallmark of DepthG is its ability to seamlessly incorporate 3D scene knowledge into unsupervised learning for 2D images without mandating depth maps as part of the network input. This elegant approach ensures that the model refrains from relying on depth information during inference when such data may not be available. DepthG operates autonomously, offering predictions on fresh, unlabeled photos without leaning on depth information.
Conclusion:
The introduction of DepthG marks a pivotal moment in the field of computer vision. Seamlessly integrating depth maps into the unsupervised learning process not only enhances semantic segmentation but also eliminates the need for depth data during inference. This innovation holds the potential to drive substantial progress in various industries, offering cost-effective and efficient solutions for tasks such as autonomous driving, retail, and face recognition, ultimately reshaping the landscape of the AI market.