
TL;DR:
- GlueGen introduces innovative alignment of encoders with T2I models, revolutionizing text-to-image capabilities.
- Existing T2I models face challenges in adaptability and multilingual support.
- GlueGen’s integration of diverse encoders enables multilingual image generation and sound-to-image conversion.
- The framework enhances image stability and accuracy, surpassing vanilla GlueNet.
- Comprehensive evaluations using FID scores and user studies validate GlueGen’s transformative potential.
Main AI News:
In the ever-evolving realm of text-to-image (T2I) models, a groundbreaking innovation has arrived in the form of GlueGen. While T2I models have proven their prowess in generating images from textual descriptions, their adaptability and versatility have remained challenging to improve. GlueGen, spearheaded by a collaborative effort involving researchers from Northwestern University, Salesforce AI Research, and Stanford University, aims to disrupt this status quo by seamlessly integrating single-modal and multimodal encoders with existing T2I models. This strategic approach simplifies upgrades and expansion possibilities, ushering in a new era of multi-language support, sound-to-image conversion, and enhanced text encoding capabilities. In this article, we delve into the transformative potential of GlueGen, exploring its pivotal role in advancing the field of X-to-image (X2I) generation.
The Current Landscape of T2I Models
Existing T2I models, particularly those rooted in diffusion processes, have achieved remarkable success in generating images based on textual prompts. However, they face a significant challenge in tightly coupling text encoders with image decoders, rendering modifications and upgrades a complex endeavor. Some notable T2I approaches include Generative Adversarial Nets (GANs), Stack-GAN, Attn-GAN, SD-GAN, DM-GAN, DF-GAN, LAFITE, as well as auto-regressive transformer models like DALL-E and CogView. Furthermore, diffusion models like GLIDE, DALL-E 2, and Imagen have played a significant role in the landscape of image generation within this domain.
T2I Evolution and Its Challenges
T2I generative models have made substantial strides, driven by algorithmic enhancements and the availability of extensive training data. Diffusion-based T2I models excel in image quality but grapple with issues of controllability and composition, often necessitating intricate engineering to achieve desired outcomes. Additionally, a prominent limitation lies in their predominant training on English text captions, restricting their utility in multilingual contexts.
The GlueGen Revolution
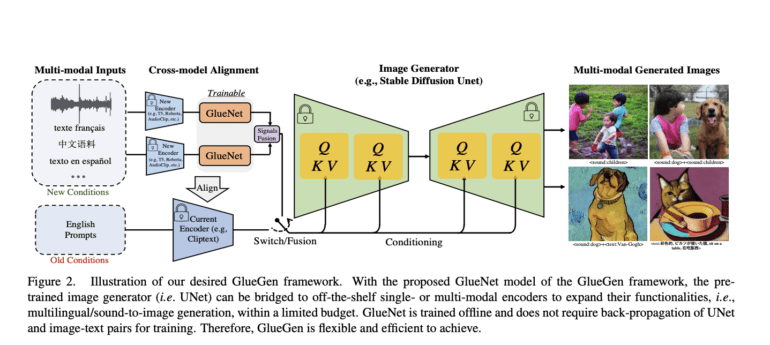
Enter the GlueGen framework, which introduces GlueNet, a transformative solution for aligning features from diverse single-modal and multimodal encoders with the latent space of existing T2I models. This innovative approach leverages a novel training objective that harnesses parallel corpora to harmonize representation spaces across different encoders. GlueGen’s capabilities extend to integrating multilingual language models like XLM-Roberta with T2I models, enabling high-quality image generation from non-English captions. Furthermore, it paves the way for the alignment of multi-modal encoders, such as AudioCLIP, with the Stable Diffusion model, thereby enabling sound-to-image conversion.
Unleashing Versatility
GlueGen offers the unique capability to align a wide array of feature representations, enabling the seamless integration of new functionality into existing T2I models. Its prowess is most evident in aligning multilingual language models, such as XLM-Roberta, with T2I models to produce top-tier images from non-English textual prompts. Additionally, GlueGen facilitates the alignment of multi-modal encoders, such as AudioCLIP, with the Stable Diffusion model, opening new horizons in sound-to-image conversion. Notably, this method enhances image stability and accuracy compared to vanilla GlueNet, thanks to its innovative objective re-weighting technique. Comprehensive evaluations are conducted using FID scores and user studies, further attesting to the transformative power of GlueGen in the T2I landscape.
Conclusion:
GlueGen’s introduction represents a significant advancement in the text-to-image model landscape. Its ability to seamlessly integrate various encoders, enable multilingual image generation, and support sound-to-image conversion sets a new standard for T2I models. This innovation positions GlueGen as a driving force in making T2I technology more versatile and adaptable, with the potential to cater to a broader market, including multilingual and multimodal applications.