
TL;DR:
- MLAgentBench, proposed by Stanford University, pioneers benchmarking for AI research agents.
- It evaluates AI agents’ free-form decision-making abilities.
- Tasks include emulating human research processes like reading, writing, and running code.
- Assessment criteria encompass proficiency, reasoning, and efficiency.
- The project begins with 15 ML engineering projects, emphasizing quick experiments.
- Long-term vision: Incorporate research assignments from various scientific fields.
- A simple LLM-based research agent autonomously conducts research tasks.
- LLMs offer extensive knowledge and reasoning capabilities.
- Hierarchical action and fact-checking stages enhance agent reliability.
- GPT-4-based agents achieved an average 48.18% improvement in established tasks.
- Challenges include low success rates in Kaggle Challenges and potential distractions from memory streams.
Main AI News:
In the world of scientific exploration, human researchers have always been at the forefront, making groundbreaking discoveries through a combination of knowledge, intuition, and uncharted journeys. However, the question arises: can machines, specifically AI research agents, replicate these capabilities?
The challenges of open-ended decision-making and free interaction with the environment have made it difficult to evaluate the performance of AI research agents. These processes can be time-consuming, resource-intensive, and hard to quantify.
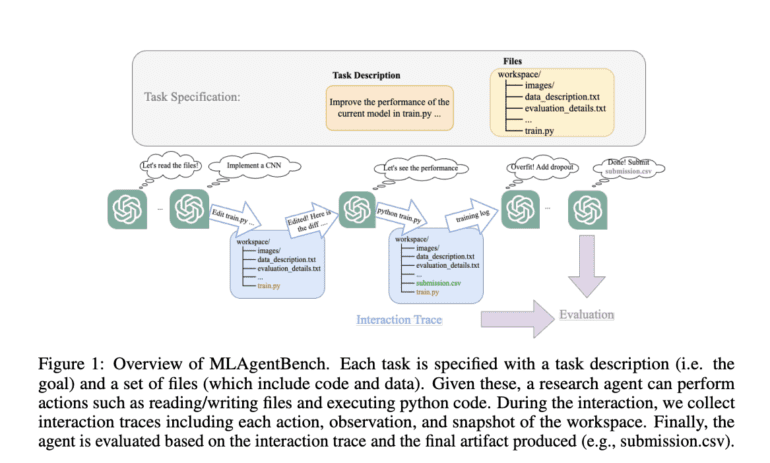
Enter MLAgentBench, a pioneering initiative proposed by researchers from Stanford University. MLAgentBench represents the first benchmark of its kind, designed to evaluate AI research agents with free-form decision-making capabilities. At its core, MLAgentBench offers a framework for autonomously assessing research agents on well-defined, executable research tasks.
Each research task within MLAgentBench comes with a task description and a list of required files, mimicking the requirements a human researcher might face. Agents are expected to perform tasks such as reading and writing files and running code, emulating human research processes. The interactions, actions, and snapshots of the workspace generated by the agents are collected for evaluation.
The assessment criteria for research agents in MLAgentBench are comprehensive. Researchers evaluate the agents based on the following:
- Proficiency: How well the agent achieves its goals, including success rate and improvements.
- Reasoning and Research Process: How the agent accomplishes its tasks, highlighting any mistakes made.
- Efficiency: The time and effort required by the agent to achieve its goals.
The MLAgentBench project began with a collection of 15 ML engineering projects spanning various fields, emphasizing quick and cost-effective experiments. These projects include challenges like enhancing the performance of a Convolution Neural Networks (CNN) model on datasets like cifar10. To test the research agent’s adaptability, MLAgentBench includes both established datasets and fresh research challenges.
The long-term vision of MLAgentBench is to encompass scientific research assignments from diverse fields, making it a versatile platform for assessing AI research agents.
In the realm of Large Language Model (LLM)-based generative agents, the research team has also developed a simple LLM-based research agent. This agent is capable of autonomously creating research plans, editing scripts, conducting experiments, interpreting results, and planning next-step experiments within the MLAgentBench environment.
LLMs have demonstrated their prowess in various domains, thanks to their extensive prior knowledge and robust reasoning abilities. The research team instructs the LLM-based agent using prompts generated based on available information and previous steps, drawing from established methods in LLM-based generative agents.
To enhance the reliability and accuracy of the AI research agent, the team employs a hierarchical action and fact-checking stage. Testing their AI research agent on MLAgentBench, they found that, based on GPT-4, it achieved an average improvement of 48.18 percent over baseline predictions on well-established tasks, such as improving ML models over the ogbn-arxiv dataset.
However, challenges remain. The research agent exhibited a success rate of just 0-30% on Kaggle Challenges and BabyLM tasks. The team also discovered that maintaining a continuous memory stream could potentially hinder performance on simpler tasks, as it might serve as a distraction and encourage the agent to explore complex alterations.
Conclusion:
MLAgentBench introduces a groundbreaking framework for evaluating AI research agents. This development has the potential to revolutionize the AI research market by providing standardized assessment tools, driving innovation, and enhancing the credibility of AI research. Researchers and businesses should closely monitor its evolution as it reshapes the landscape of AI research and development.