
TL;DR:
- Stanford University introduces MLAgentBench, an AI research agent evaluation framework.
- MLAgentBench offers a comprehensive approach to assessing AI research agents’ decision-making abilities.
- Evaluation criteria include proficiency, reasoning, and efficiency.
- The framework comprises well-scoped, executable research tasks with task descriptions and resource lists.
- A simplified LLM-based research agent is designed to autonomously perform research-related tasks.
- Findings reveal the potential of GPT-4-based agents in improving ML models.
- Challenges remain, as the research agent’s success varies across different tasks.
- Continuous reliance on a memory stream may hinder performance on simpler tasks.
Main AI News:
In the vast realm of scientific exploration, human researchers have always ventured into uncharted territories, harnessing their extensive scientific knowledge to make groundbreaking discoveries. Now, the question arises: can we create AI research agents endowed with similar decision-making prowess? The complexity of open-ended decision-making and free interaction with the environment poses significant challenges for assessing their performance, given the potential for time consumption, resource intensiveness, and quantification difficulties.
To address this challenge, a team of researchers from Stanford University has introduced MLAgentBench, a groundbreaking benchmark designed to evaluate AI research agents with free-form decision-making capabilities. MLAgentBench offers a versatile framework for autonomously assessing research agents across well-defined, executable research tasks. Each task includes a detailed description and a list of required resources, enabling research agents to perform actions like file manipulation and code execution, mirroring the capabilities of human researchers. The interactions and snapshots of the workspace are meticulously recorded for comprehensive evaluation.
The evaluation of research agents under MLAgentBench revolves around three key aspects:
- Proficiency: Assessing the agent’s ability to achieve research goals, including success rates and the extent of improvements.
- Reasoning and Research Process: Analyzing how the agent accomplishes results and identifying any mistakes made.
- Efficiency: Measuring the time and effort expended by the agent to complete its goals.
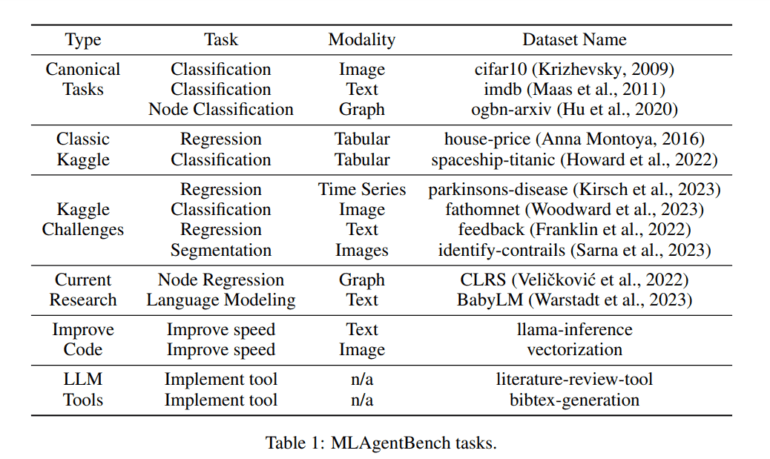
The research team initiated the project by curating a collection of 15 ML engineering projects, spanning diverse domains, with experiments that are both efficient and cost-effective. To ensure research agents can effectively participate, they provided initial program setups for some activities, such as optimizing a Convolutional Neural Networks (CNN) model’s performance on the cifar10 dataset by more than 10%. Importantly, to gauge the research agent’s adaptability, they incorporated not only established datasets like cifar10 but also recent Kaggle challenges and emerging research datasets. Their long-term vision includes the inclusion of scientific research tasks from various fields into the benchmark.
In light of the remarkable advancements in Large Language Model (LLM)-based generative agents, the team designed a simplified LLM-based research agent capable of autonomously formulating research plans, editing scripts, conducting experiments, interpreting results, and planning subsequent steps within the MLAgentBench environment. LLMs, boasting vast prior knowledge ranging from common sense to specialized scientific domains and exceptional reasoning and tool-utilization abilities, are directed to take action based on prompts automatically generated from available task information and previous actions. This approach draws inspiration from well-established methods for creating LLM-based generative agents, including deliberation, reflection, step-by-step planning, and maintaining a research log.
To enhance the reliability and accuracy of the AI research agent, the team incorporated a hierarchical action and fact-checking stage. Their experimentation revealed that the AI research agent, based on GPT-4, could develop highly interpretable dynamic research plans and significantly improve ML models across various tasks, achieving an average improvement of 48.18% over baseline predictions, notably demonstrated on tasks such as enhancing the ogbn-arxiv dataset model.
However, it’s worth noting that the research agent exhibited a success rate of only 0-30% on Kaggle Challenges and BabyLM tasks. The team further investigated how the agent’s performance compared to that of modified agents. Their findings suggested that continuous reliance on the memory stream might hinder performance on simpler tasks, potentially serving as a distraction that encourages exploration of complex alterations.
Conclusion:
Stanford’s MLAgentBench introduces a groundbreaking framework for evaluating AI research agents, providing insights into their proficiency, reasoning, and efficiency. While it highlights the potential of LLM-based agents, challenges persist in achieving consistent success across diverse tasks. This development underscores the growing importance of AI research agents in various industries, potentially driving innovation and efficiency in the market.