
TL;DR:
- “MotionDirector” introduces a dual-path architecture for text-to-video AI models.
- It empowers users to customize video motions while maintaining appearance diversity.
- The dual architecture includes spatial and temporal pathways, enhancing motion and appearance learning.
- Benchmarks show MotionDirector’s superior performance in motion fidelity and controllable generation.
- Despite room for improvement in multi-subject motion learning, MotionDirector offers flexibility and customization.
- It represents a significant milestone in the evolution of text-to-video AI models.
Main AI News:
In the rapidly evolving landscape of text-to-video diffusion models, recent advancements have ushered in a new era of creativity and innovation. These models empower users to transform textual descriptions into captivating videos, blurring the lines between reality and imagination. While these foundational models have excelled in generating images that align with specific appearances, styles, and subjects, a frontier yet to be fully explored is the realm of customizing motion in text-to-video generation. Users increasingly desire the ability to craft videos with precise and tailored motions, such as a car gracefully transitioning from a forward motion to a left turn. Thus, the imperative arises to adapt diffusion models to create highly specific content that caters to individual preferences and requirements.
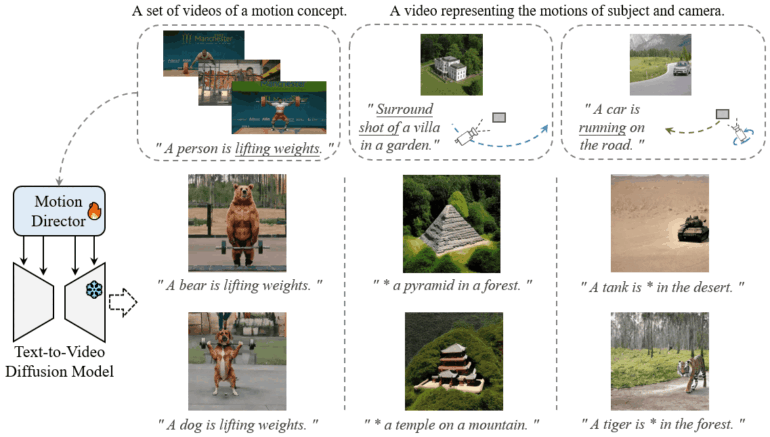
Introducing “MotionDirector”: Redefining Motion Customization While Preserving Appearance Diversity
In response to this uncharted territory, the authors of this paper unveil “MotionDirector,” a groundbreaking solution poised to revolutionize text-to-video generation. MotionDirector stands as a beacon of innovation, facilitating motion customization while preserving the richness of appearance diversity. The core technique leverages a dual-path architecture meticulously designed to teach models the nuances of both motion and appearance, thereby enhancing the ability to craft personalized video content.
The Dual Architecture: Bridging the Gap between Appearance and Motion
At the heart of MotionDirector lies its dual architecture, a masterful combination of spatial and temporal pathways. The spatial path boasts a foundational model integrated with trainable spatial LoRAs (Low-Rank Adaptations) strategically embedded within its transformer layers for each video. These spatial LoRAs, honed through rigorous training using randomly selected single frames in each step, adeptly capture the visual attributes of input videos.
Conversely, the temporal pathway mirrors the foundational model but shares the spatial LoRAs from the spatial path, adapting them to the appearance of the input video. Moreover, the temporal transformers in this pathway are further empowered with temporal LoRAs, cultivated through the assimilation of multiple frames from the input videos. These temporal LoRAs serve as the key to understanding the intricate patterns of motion inherent in the videos.
The Synergy of Appearance and Motion: A Symphony of Customization
Through the strategic deployment of trained temporal LoRAs, the foundation model seamlessly synthesizes videos that encapsulate learned motions while embracing diverse appearances. The dual architecture’s ingenious decoupling of appearance and motion empowers MotionDirector to isolate these elements from various source videos and harmoniously combine them, resulting in a symphony of customization.
Proven Performance: MotionDirector’s Triumph
To substantiate its prowess, researchers conducted rigorous benchmarks on MotionDirector, involving over 80 distinct motions and 600 text prompts. On the UCF Sports Action benchmark, comprising 95 videos and 72 text prompts, MotionDirector garnered the preference of human raters approximately 75% of the time, showcasing superior motion fidelity compared to base models. The second benchmark, LOVEU-TGVE-2023, featuring 76 videos and 532 text prompts, witnessed MotionDirector’s triumph over other controllable generation and tuning-based methods. These results underscore MotionDirector’s capacity to customize numerous base models, producing videos characterized by diversity and the embodiment of desired motion concepts.
A Glimpse into the Future: Advancing the Frontier of Video Generation
MotionDirector stands as a beacon of promise in the landscape of text-to-video diffusion models, excelling in the acquisition and adaptation of specific motions, whether of subjects or cameras. Its capacity to generate videos spanning a spectrum of visual styles is a testament to its potential.
Room for Growth: Enhancing the Multi-Subject Motion Learning
While MotionDirector thrives in its current form, there is room for improvement, particularly in the realm of learning the motion of multiple subjects within reference videos. Nevertheless, even with this constraint, MotionDirector holds the promise of expanding flexibility in video generation. It empowers users to craft videos meticulously tailored to their preferences and requirements, marking a pivotal moment in the evolution of text-to-video AI models.
Conclusion:
“MotionDirector” presents a game-changing advancement in the text-to-video AI market. Its dual-path architecture, which decouples appearance and motion, addresses a crucial gap in customization capabilities. This innovation positions MotionDirector as a leader in providing diverse and tailored video content, offering significant potential for market growth and catering to evolving user preferences and requirements.