
TL;DR:
- The peer-review process in scholarly publications remains a bastion of integrity, ensuring accuracy and quality in research.
- Large language models (LLMs) are being explored as a solution to address challenges in the peer-review process, such as prolonged review times and reviewer shortages.
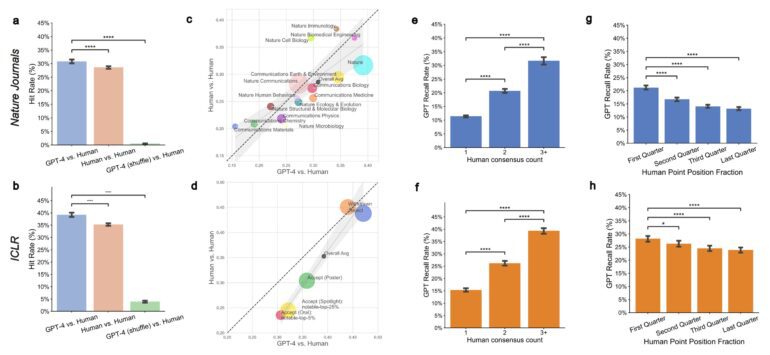
- Stanford University researchers found that LLM-generated reviews overlapped substantially (31% to 39%) with human reviewers, with even better performance on weaker submissions (44% overlap).
- Authors surveyed indicated that LLM feedback was often found to be as helpful or more helpful than feedback from human reviewers.
- LLMs can complement human expertise, particularly in guiding authors who need substantial revisions to their papers.
- However, LLMs should not replace human oversight, as they have limitations, including vagueness and a lack of in-depth critique in certain areas.
- Collaborative integration of LLMs and human expertise has the potential to expedite reviews and enhance the quality of scholarly publications.
Main AI News:
In the age of rampant misinformation and deceit on the internet, a beacon of integrity shines in the world of academia—the peer-review process for scholarly publications. This cornerstone of academic rigor, wherein experts scrutinize research articles for accuracy, accountability, and quality, remains steadfast in its commitment to upholding the highest standards of honesty. The peer-review process, dating back to the 17th century, plays a pivotal role in ensuring that the best ideas ultimately prevail.
Pulitzer Prize-winning journalist Chris Mooney aptly captures the essence of peer review, stating, “Even if individual researchers are prone to falling in love with their own theories, the broader process of peer review and institutionalized skepticism are designed to ensure that, eventually, the best ideas prevail.”
Currently, there are approximately 5.14 million peer-reviewed articles published annually, demanding over 100 million hours of rigorous evaluation. However, the process is not without its challenges, including prolonged review times, soaring costs, and the scarcity of qualified reviewers who often work pro bono.
Enter large language models (LLMs) as potential game-changers in this landscape. Researchers at Stanford University have explored how LLMs can contribute to the peer-review process, addressing the issues of prolonged wait times and reviewer shortages, which collectively cost an estimated $2.5 billion annually.
Weixin Liang, an author of the paper titled “Can large language models provide useful feedback on research papers? A large-scale empirical analysis,” underscores the importance of timely feedback. Junior researchers and those from under-resourced backgrounds face significant hurdles in obtaining timely reviews for their work.
The Stanford study compared reviewer feedback on thousands of papers from renowned journals and conferences with reviews generated by GPT-4, a large language model. Surprisingly, they found a substantial overlap of 31% to 39% in the points raised by both human reviewers and the AI-generated counterparts. Notably, on weaker submissions that were ultimately rejected, GPT-4 outperformed human reviewers, aligning with them 44% of the time.
Additionally, when authors were surveyed about the utility of LLM-generated feedback, more than half found it helpful or very helpful. Remarkably, 80% of authors expressed that LLM feedback surpassed the assistance provided by “at least some” human reviewers.
Weixin Liang emphasizes that LLM and human feedback can coexist harmoniously. This collaborative approach is particularly beneficial for authors in need of substantial revisions to their papers, enabling them to address critical concerns early in the scientific process.
One author, benefiting from GPT-4’s insights, noted that the AI highlighted crucial points that human reviewers had overlooked. The AI review suggested visualizations for improved interpretability and addressed data privacy issues, underscoring the value of AI in complementing human expertise.
However, the report issues a vital caveat: LLMs should not be viewed as a replacement for human oversight. Some limitations, such as vague feedback and a lack of in-depth critique of model architecture and design, were noted. Weixin Liang emphasizes, “Expert human feedback will still be the cornerstone of rigorous scientific evaluation. While comparable and even better than some reviewers, the current LLM feedback cannot substitute specific and thoughtful human feedback by domain experts.”
Conclusion:
The integration of large language models into the peer-review process holds promise as a valuable tool to expedite reviews and improve the overall quality of scholarly publications. While LLMs offer considerable benefits, they are most effective when used in conjunction with the indispensable expertise of human reviewers. This collaborative approach has the potential to further elevate the standards of academic research and ensure the dissemination of the best ideas to the global community.