
TL;DR:
- PaLI-3, Google AI’s latest Vision Language Model (VLM), challenges larger models with impressive performance.
- VLMs combine language understanding and image recognition, offering diverse applications in AI.
- Google’s research highlights the effectiveness of contrastive pre-training for VLMs, elevating PaLI models.
- PaLI-3, a 5-billion-parameter VLM, excels in tasks like localization and text comprehension.
- The model leverages ViT-G14 as its image encoder and boasts a 2-billion-parameter multilingual contrastive vision model.
- In the AI market, PaLI-3 redefines success, emphasizing the value of smaller-scale models for practicality and efficiency.
Main AI News:
In the fast-paced world of artificial intelligence, vision language models (VLMs) have emerged as transformative technologies, blurring the lines between textual understanding and image interpretation. Google AI’s latest creation, PaLI-3, is poised to revolutionize this landscape, offering a compact yet formidable alternative that goes toe-to-toe with models ten times its size.
The Power of Vision Language Models
VLMs like PaLI-3 are the vanguard of AI innovation, seamlessly blending natural language comprehension with image recognition prowess. Much like OpenAI’s CLIP and Google’s BigGAN, these models possess the remarkable ability to decipher textual descriptions and decode images, unlocking a myriad of applications spanning computer vision, content generation, and human-computer interaction. Their proficiency in contextualizing text with visual content has catapulted them into the spotlight, making them indispensable in the realm of artificial intelligence.
Google’s Research Triumph
The genesis of PaLI-3 owes its success to a collaborative effort by Google Research, Google DeepMind, and Google Cloud. These tech giants embarked on a journey to explore the potential of Vision Transformers (ViTs), employing a novel approach of contrastive pre-training. Remarkably, this approach has yielded a remarkable multilingual cross-modal retrieval state-of-the-art, underlining the superiority of models like SigLIP-based PaLI in tasks involving localization and text comprehension.
Scaling Up for Practicality
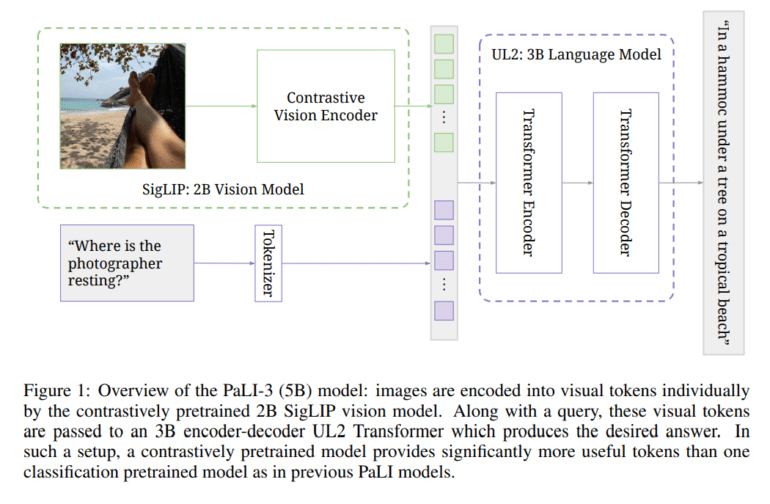
While the pursuit of larger models often dominates the AI discourse, Google’s study reinforces the value of smaller-scale models in practical applications and efficient research. Enter PaLI-3, a 5-billion-parameter VLM that punches well above its weight. Its training process combines contrastive pre-training of the image encoder on web-scale data, enhanced dataset mixing, and high-resolution training. A multilingual contrastive vision model with 2 billion parameters takes center stage, proving the dominance of contrastively pretrained models, particularly in tasks that demand spatial awareness and visual-text alignment.
The Anatomy of PaLI-3
PaLI-3 leverages a pre-trained ViT model, ViT-G14, as its image encoder, meticulously following the SigLIP training recipe. ViT-G14’s 2 billion parameters serve as the bedrock for PaLI-3’s visual capabilities. Contrastive pre-training is the key, with images and texts separately embedded and correlated. Visual tokens from ViT are seamlessly merged with text tokens, ushering them into a 3 billion parameter UL2 encoder-decoder language model for precise text generation, often prompted by task-specific queries, such as Visual Question Answering (VQA).
A Performance Benchmark
In the arena of VLMs, PaLI-3 stands tall, surpassing its larger counterparts, especially in tasks like localization and visually-situated text comprehension. The SigLIP-based PaLI model, armed with contrastive image encoder pre-training, ushers in a new era of multilingual cross-modal retrieval. PaLI-3’s comprehensive capabilities shine through in referring expression segmentation, maintaining exceptional accuracy across diverse detection task subgroups. It’s worth noting that contrastive pre-training emerges as the preferred approach for localization tasks, reinforcing the model’s proficiency. The ViT-G image encoder, an integral part of PaLI-3, exhibits remarkable prowess in a multitude of classification and cross-modal retrieval scenarios.
Conclusion:
PaLI-3’s emergence signals a paradigm shift in the Vision Language Model landscape. Google’s pioneering research showcases the potency of contrastive pre-training, enabling PaLI-3 to outperform larger counterparts. This compact yet powerful model redefines success, underscoring the significance of smaller-scale models in AI’s practical applications. PaLI-3’s impact reverberates through the market, emphasizing that innovation often thrives in compact packages.