
TL;DR:
- Retrieval augmentation transforms the landscape of Long-Form Question Answering (LFQA).
- Large Language Models (LLMs) paired with retrieved documents redefine LFQA responses.
- The University of Texas at Austin’s study explores retrieval’s impact on LFQA.
- Two research scenarios reveal significant changes in answer generation.
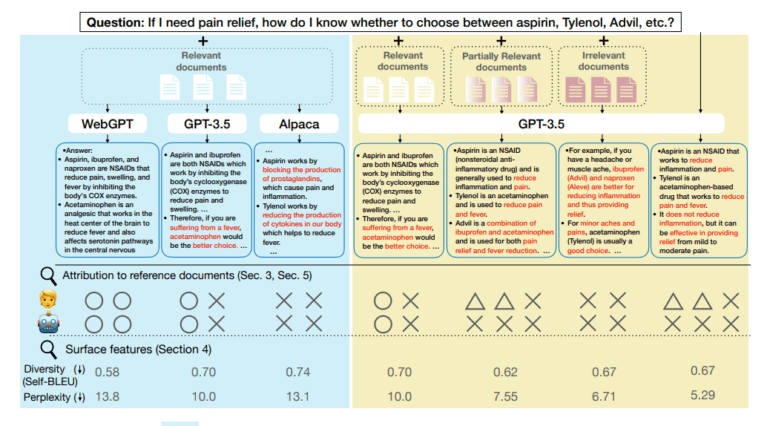
- Surface-level indicators like response length and perplexity are employed for evaluation.
- Attribution of generated answers to proof documents is a key strength of retrieval-augmented LFQA.
- Findings show retrieval enhancement leaves a distinct mark on language model creation.
- Different base LLMs may react uniquely to retrieval augmentation.
- Natural Language Inference (NLI) models excel in LFQA, nearing human agreement.
- Quality of attribution can vary widely among base LLMs, even with identical evidence.
- Attribution patterns in lengthy textual responses mirror evidence document sequences.
- Traceability decreases in the final sentence compared to earlier sentences.
Main AI News:
Long-Form Question Answering (LFQA) has emerged as a pivotal capability for today’s language models, seeking to deliver comprehensive responses to a wide array of queries. In the pursuit of crafting intricate and informative answers, LFQA systems rely on a fusion of parametric information within Large Language Models (LLMs) and dynamically retrieved documents presented during inference. This approach enables LFQA systems to go beyond mere span extraction from evidence documents and construct elaborate responses in paragraph form.
Recent years have unveiled the remarkable potential as well as the inherent fragility of large-scale LLMs in the realm of LFQA. Recognizing the need for fresh insights, researchers have proposed the augmentation of LLMs through retrieval, a strategy aimed at infusing these models with timely and contextually relevant information. However, the impact of retrieval augmentation on LLMs during the answer generation process remains relatively uncharted territory, and its outcomes do not always align with the initial expectations.
A research team hailing from the esteemed University of Texas at Austin embarked on an investigation to shed light on how retrieval influences the generation of answers in LFQA—a complex challenge within long-text generation. Their study encompasses two distinct research scenarios. In one, the language model remains constant while the evidence documents change, while the opposite is true in the other scenario. Given the intricacies of assessing LFQA quality, the researchers initially focused on quantifiable indicators such as response length and perplexity, probing for signs of coherence.
One striking attribute of retrieval-augmented LFQA systems is their ability to attribute the generated answers to the available proof documents. To assess this aspect, the researchers leveraged human annotations at the sentence level to evaluate the performance of commercially available attribution detection technologies.
Upon scrutinizing surface-level patterns, the research team arrived at a significant conclusion: retrieval enhancement leaves an indelible mark on the creation process of language models. Interestingly, not all effects are muted when irrelevant documents are introduced into the mix; for instance, the length of generated responses may exhibit noteworthy variations. In contrast, when pertinent in-context evidence is supplied, LLMs tend to produce more unexpected phrases. Furthermore, it is worth noting that even when presented with identical sets of evidence documents, different base LLMs can exhibit varying responses to retrieval augmentation. The freshly annotated dataset established by the researchers serves as a gold standard for evaluating attribution assessments.
The study’s findings extend beyond the realm of simple observations. They highlight that Natural Language Inference (NLI) models, originally designed for factoid QA, also excel in the context of LFQA, surpassing chance by a significant margin but falling short of a human agreement by 15% in terms of accuracy.
The research underscores that the quality of attribution can vary significantly among base LLMs, even when confronted with identical sets of documents. Additionally, it sheds light on the attribution patterns that govern the production of lengthy textual responses. Remarkably, the generated text tends to mirror the sequence of in-context evidence documents, even when these documents constitute a concatenation of multiple papers. Intriguingly, the traceability of the final sentence is noticeably lower than that of earlier sentences.
Conclusion:
This research underscores the transformative potential of retrieval augmentation in Long-Form Question Answering. The ability to infuse Large Language Models with contextually relevant information not only enhances response quality but also opens new avenues for innovation in the information retrieval market. Firms developing LFQA systems and NLI models should take note of these findings as they shape the future of AI-driven information access and dissemination.