
TL;DR:
- LAMP is an innovative framework for text-to-video generation, addressing the challenge of limited data.
- It employs few-shot learning to enable motion pattern recognition with just 8 to 16 videos on a single GPU.
- LAMP enhances video quality and generation freedom by combining text-to-image techniques with motion learning layers.
- The framework extends beyond text-to-video, finding applications in image animation and video editing.
- Extensive experiments confirm LAMP’s effectiveness in mastering motion patterns and producing high-quality videos.
Main AI News:
In a pioneering study, a team of researchers has introduced a game-changing framework known as LAMP, which leverages few-shot learning to tackle the intricate task of text-to-video (T2V) generation. While significant progress has been made in the realm of text-to-image (T2I) generation, extending this capability to text-to-video has proven to be a formidable challenge. Existing methods often demand copious text-video pairs and substantial computational resources, resulting in video generation that closely aligns with template videos. Balancing the freedom of generation with resource efficiency remains a daunting trade-off.
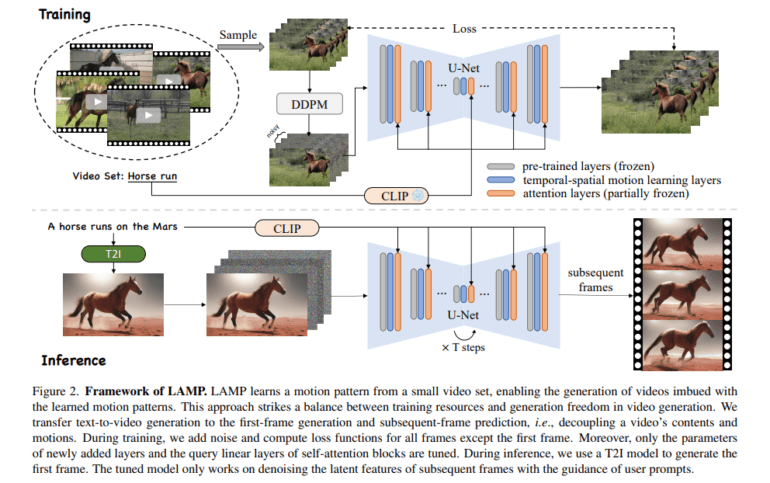
Addressing this challenge, a collaborative effort from VCIP, CS, Nankai University, and MEGVII Technology has yielded the innovative LAMP framework. LAMP stands as a few-shot-based tuning framework, enabling a text-to-image diffusion model to acquire specific motion patterns using as few as 8 to 16 videos on a single GPU. This novel approach involves a first-frame-conditioned pipeline that harnesses a pre-trained text-to-image model for content generation, channeling the video diffusion model’s focus toward mastering motion patterns. By utilizing established text-to-image techniques for content generation, LAMP not only enhances video quality but also amplifies generation freedom.
To capture the temporal intricacies of videos, the researchers extend the 2D convolution layers of the pre-trained T2I model to encompass temporal-spatial motion learning layers. Furthermore, they adapt attention blocks to operate at the temporal level. Additionally, a shared-noise sampling strategy is introduced during inference, enhancing video stability with minimal computational overhead.
Beyond text-to-video generation, LAMP exhibits versatility, finding applications in real-world image animation and video editing, solidifying its status as a multifaceted tool with broad-ranging utility.
Extensive experimentation has been conducted to evaluate LAMP’s performance in mastering motion patterns with limited data and generating high-quality videos. The results unequivocally affirm LAMP’s ability to excel in these objectives. It skillfully strikes a balance between the training burden and generation freedom while mastering the nuances of motion patterns. By harnessing the strengths of T2I models, LAMP emerges as a potent solution in the realm of text-to-video generation.
Conclusion:
The introduction of LAMP marks a significant milestone in text-to-video generation. This groundbreaking framework harnesses few-shot learning to conquer the challenge of translating text prompts into video sequences, all while learning from a small video dataset. LAMP’s first-frame-conditioned pipeline, temporal-spatial motion learning layers, and shared-noise sampling strategy collectively elevate video quality and stability. Its versatility extends its utility to a spectrum of tasks beyond text-to-video generation. Through comprehensive experimentation, LAMP has unequivocally demonstrated its prowess in mastering motion patterns with limited data and delivering high-quality videos, offering a promising avenue in the domain of text-to-video generation.