
TL;DR:
- BSM (Branch-Solve-Merge) program enhances Large Language Models (LLMs) for complex language tasks.
- It includes branching, solving, and merging modules for sub-task planning and execution.
- BSM improves human-LLM agreement, reduces biases, and empowers LLaMA-2-chat to compete with GPT-4.
- It enhances story coherence and constraint satisfaction in text generation.
- BSM’s parallel decomposition approach addresses challenges in LLM evaluation and text generation.
- BSM’s application extends across various LLMs and domains, even outperforming GPT-4.
Main AI News:
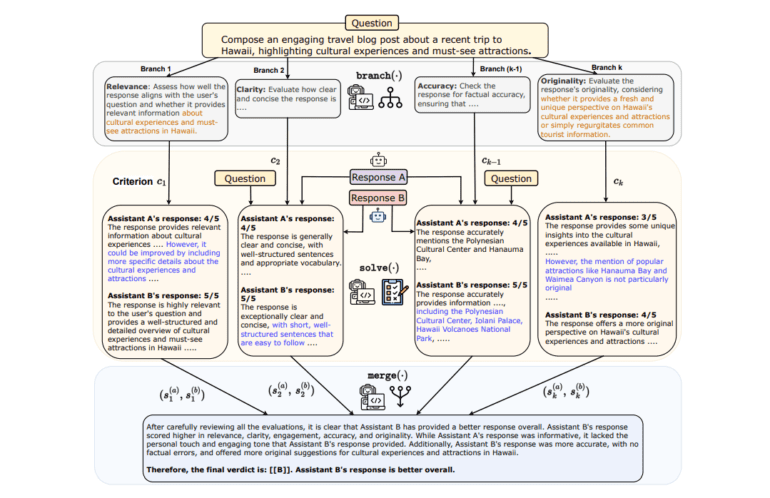
In the realm of advanced language processing, researchers from Meta and the University of North Carolina at Chapel Hill have unveiled a groundbreaking program known as Branch-Solve-Merge (BSM). This innovative software is designed to elevate the performance of Large Language Models (LLMs) when faced with intricate natural language tasks. BSM introduces a three-pronged approach, encompassing branching, solving, and merging modules to strategically plan, decipher, and consolidate sub-tasks. When applied to LLM response evaluation and controlled text generation in models such as Vicuna, LLaMA-2-chat, and GPT-4, BSM not only elevates the level of agreement between humans and LLMs but also mitigates inherent biases. Remarkably, it empowers LLaMA-2-chat to either match or surpass GPT-4’s capabilities across diverse domains. Furthermore, it substantially enhances narrative coherence and user satisfaction in constraint-driven story generation.
While Large Language Models excel in handling multifaceted language tasks, they often encounter challenges when confronted with complexity. BSM, as an LLM program, introduces a novel approach by dissecting tasks into manageable steps, each parameterized with unique prompts. This marks a departure from the traditional sequential methodologies. BSM is specifically tailored for tasks like LLM evaluation and constrained text generation, which thrive on parallel decomposition. This revolutionary process presents a valuable solution for evaluating LLMs in the context of complex text generation tasks, particularly those rooted in planning and constraints, thus addressing the need for a holistic evaluation approach.
Despite their prowess in text generation, Large Language Models often struggle with intricate, multi-objective tasks. Enter BSM, a collaborative effort between UNC-Chapel Hill and Meta researchers, aimed at tackling these formidable challenges. BSM employs branch, solve, and merge modules to break down tasks into parallel sub-tasks. When applied to LLM response evaluation and constrained text generation, BSM not only elevates correctness and consistency but also enhances constraint satisfaction in these tasks. This monumental achievement benefits a multitude of LLMs, including LLaMA-2-chat, Vicuna, and GPT-4. BSM emerges as a promising solution to enhance LLM performance in the realm of intricate language tasks.
BSM’s methodology revolves around the decomposition of complex language tasks into three distinct modules: branch, solve, and merge. When deployed in the context of LLM response evaluation and constrained text generation, BSM brings about improvements in correctness and consistency while simultaneously reducing biases. This versatility extends its application across various LLMs, offering a promising avenue for the enhancement of LLM evaluation across diverse tasks and scales.
The impact of BSM on LLM-human agreement is remarkable, achieving a noteworthy 12-point enhancement for LLaMA-2-70B-chat in turn-1 and turn-2 questions. Furthermore, it outperforms in terms of self-consistency, effectively reducing biases by an impressive 34% in both position bias and length bias. BSM, in its transformative role, empowers even less powerful open-source models like LLaMA-2 to compete head-to-head with the formidable GPT-4. Its performance transcends multiple domains, consistently matching or approaching GPT-4’s capabilities in various categories, while simultaneously improving agreement scores and mitigating position bias. Notably, it excels in grading reference-based questions, surpassing both LLaMA-2-70B-chat and GPT-4 in categories such as Mathematics, thereby augmenting agreement scores and mitigating position bias.
Conclusion:
The BSM method stands as a potent response to the critical challenges posed by LLM evaluation and text generation. With its branch, solve, and merge modules, it significantly enhances LLM response evaluation and constrained text generation, resulting in improved correctness, consistency, and human-LLM agreement. Moreover, BSM plays a pivotal role in mitigating biases, elevating story coherence, and enhancing constraint satisfaction. Its effectiveness spans different LLMs and domains, even surpassing GPT-4’s performance in various categories. BSM, with its versatility and promise, emerges as a powerful approach to enhance LLM performance across a multitude of tasks.