
TL;DR:
- LLaRP, a novel approach by Apple, repurposes Large Language Models (LLMs) for Reinforcement Learning (RL) in Embodied Artificial Intelligence (AI).
- Achieves a remarkable 1.7 times higher success rate than established baselines and zero-shot LLM applications.
- LLaRP adapts pre-trained LLMs for multi-modal decision-making, casting it as a Partially-Observable Markov Decision Process (POMDP).
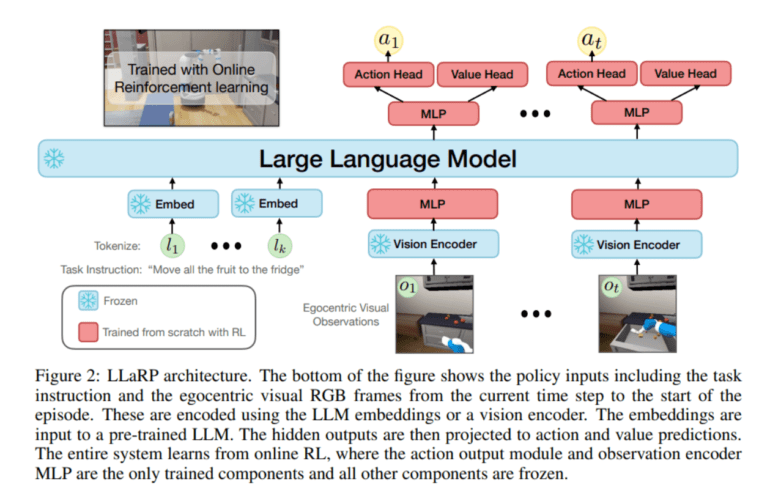
- LLaRP policy utilizes LLM embeddings and online RL, with only action output and observation encoder as trainable components.
- Demonstrates robust generalization capabilities evaluated on Paraphrastic Robustness (PR) and Behavior Generalization (BG) axes.
- Outperforms LSTM-based policies and zero-shot LLM applications, even with novel instructions and unseen tasks.
- Infusing LLM-encoded world knowledge enhances sample efficiency and reduces supervision requirements.
- Introduces the Language Rearrangement task, enabling research in Embodied AI with 150,000 distinct language instructions.
Main AI News:
Large Language Models (LLMs) have catalyzed a paradigm shift in language comprehension, offering a promising avenue for their application in intricate embodied visual tasks. This burgeoning frontier endeavors to ascertain whether these models can serve as the bedrock for adaptable, versatile policies that facilitate decision-making, seamlessly adapting to novel scenarios.
In their groundbreaking paper titled “Large Language Models as Generalizable Policies for Embodied Tasks,” a dedicated team of researchers at Apple introduces the Large Language model Reinforcement Learning Policy (LLaRP). LLaRP ingeniously repurposes LLMs for the rigors of Reinforcement Learning (RL) challenges within the realm of Embodied Artificial Intelligence (AI). The results are nothing short of astonishing, with LLaRP achieving a remarkable 1.7 times higher success rate compared to established baselines and zero-shot LLM applications.
The LLaRP methodology represents a pioneering endeavor in harnessing pre-trained LLMs to navigate the intricacies of multi-modal decision-making, inherent to embodied tasks. At its core, the challenge is framed as a Partially-Observable Markov Decision Process (POMDP). The policy’s inputs encompass task instructions and egocentric visual RGB frames from the current time step, encoded using LLM embeddings or a vision encoder. These embeddings serve as the input to a pre-trained LLM, with the hidden outputs subsequently translated into action and value predictions. It’s noteworthy that the entire system undergoes learning through online RL, with the action output module and observation encoder MLP being the only trainable components, while the others remain static.
The research team demonstrates that leveraging a pre-trained and unchanging LLM as a Vision-Language Model (VLM) policy with learned input and output adapter layers leads to a policy that exhibits robust generalization capabilities. This policy undergoes training via online RL, with its generalization prowess evaluated along two axes: Paraphrastic Robustness (PR) and Behavior Generalization (BG).
LLaRP undergoes a rigorous evaluation encompassing over 1,000 unseen tasks, spanning the dimensions of PR and BG, and delivers an impressive 42% success rate. This not only surpasses the performance of alternative LSTM-based policies at 25% but also outperforms zero-shot LLM applications at 22%. Importantly, LLaRP emerges as the frontrunner when confronted with novel instructions and previously unseen tasks. Furthermore, the research team demonstrates that the LLaRP LLM-based policy provides a substantial performance boost in a distinct domain, Atari, when compared to a Transformer baseline.
The researchers additionally unearth the advantages of infusing LLM-encoded world knowledge into RL. LLM-based models exhibit superior sample efficiency when contrasted with other conventional architectures, both in basic Proximal Policy Optimization (PPO) RL and continual learning settings. Moreover, LLaRP proves to be more efficient in terms of required supervision, eclipsing commonly used imitation learning techniques.
In an encouraging move to foster further exploration of generalization in Embodied AI, the researchers introduce the Language Rearrangement task. This task entails a staggering 150,000 distinct language instructions, each equipped with automatically generated rewards. It provides an invaluable framework for ongoing research in the field.

Source: Synced
Conclusion:
LLaRP’s groundbreaking approach to integrating LLMs into Embodied AI promises transformative outcomes. With superior success rates, robust generalization capabilities, and enhanced efficiency, it opens up exciting possibilities for the future of AI research and development. Businesses in the AI market should closely monitor and potentially invest in these advancements to stay competitive in this rapidly evolving landscape.