
TL;DR:
- Spectron is a groundbreaking spoken language AI model developed by Google Research and Verily AI.
- Unlike traditional language models, Spectron directly processes spectrograms as both input and output.
- This model eliminates inductive biases, enhancing representational fidelity.
- Spectron transcribes and generates text continuations, improving audio generation quality.
- Its architecture utilizes a pre-trained speech encoder and language decoder, offering text and speech continuations.
- Challenges include time-consuming spectrogram frame generation and the inability to parallelize text and spectrogram decoding.
Main AI News:
In the realm of language models, the dawn of Spectron marks a paradigm shift. While speech continuation and question-answering Language Model Machines (LLMs) have already proven their worth across diverse sectors, Spectron emerges as the trailblazer, designed to revolutionize the way we interact with spoken language.
Traditionally, LLMs like GPT-3 have relied on deep-learning architectures, pre-trained on massive text datasets, enabling them to grasp the intricacies of human language and generate contextually relevant and coherent text. However, Google Research and Verily AI have ventured into uncharted territory with Spectron, a novel spoken language model.
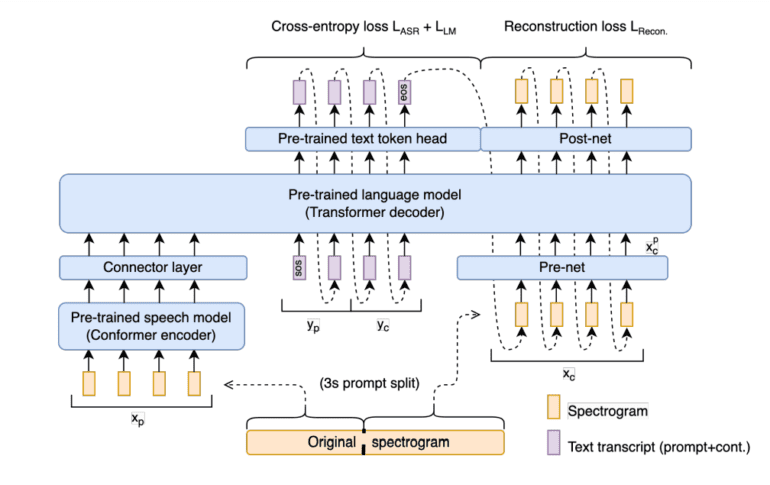
What sets Spectron apart is its unique ability to directly process spectrograms as both input and output. A spectrogram, for the uninitiated, is a visual representation of the spectrum of frequencies in an audio signal over time. Spectron leverages intermediate projection layers, tapping into the audio capabilities of a pre-trained speech encoder, all while eradicating inductive biases that typically plague pre-trained encoders and decoders. This model achieves it all without compromising representational fidelity.
Spectron serves as an ‘intermediate scratchpad,’ transcribing and generating text continuations, while being further conditioned for audio generation. The model excels in capturing richer, longer-range information about the signal’s shape, utilizing this knowledge to align with the higher-order temporal and feature deltas of the ground truth through spectrogram regression.
The architecture of Spectron hinges on a pre-trained speech encoder and a pre-trained language decoder. A speech utterance acts as input to the encoder, resulting in linguistic features that serve as the decoder’s prefix. This synchronized dance aims to minimize cross-entropy jointly, offering both text and speech continuations from a single spoken speech prompt.
What’s truly groundbreaking is the dual application of Spectron’s architecture to decode both intermediate text and spectrograms. This innovation not only capitalizes on pre-training in the text domain to enhance speech synthesis but also elevates the quality of synthesized speech, akin to the strides made in text-based language models. While the potential of Spectron is undeniably promising, it comes with its share of complexities. The process demands the generation of multiple spectrogram frames, which can be time-consuming. Moreover, the model currently cannot parallelize text and spectrogram decoding. However, the research team is committed to addressing these limitations, with a focus on developing a parallelized decoding algorithm for the future.
Conclusion:
The introduction of Spectron represents a significant leap forward in the field of spoken language AI. Its unique approach to processing spectrograms opens up new possibilities for improving speech synthesis and understanding. While there are technical challenges to overcome, the potential for enhanced user experiences and productivity across various industries is substantial, making Spectron a game-changer in the market.