
TL;DR:
- Large language models (LLMs) like ChatGPT and Llama are potent in natural language processing but face high operational costs.
- Scaling LLMs for numerous users and complex tasks escalates expenses, emphasizing the need for efficient decoding.
- FlashAttention v2 addresses the challenge by optimizing attention operations during decoding.
- Flash-Decoding, a revolutionary method, utilizes GPU parallelization to enhance efficiency and reduce costs.
- Benchmark experiments reveal an 8-fold speed increase in decoding with Flash-Decoding, even for longer sequences.
- This advancement significantly improves the efficiency and scalability of LLMs in various applications.
Main AI News:
In the realm of natural language processing, large language models (LLMs) like ChatGPT and Llama have revolutionized text generation and code completion. However, their operational costs have posed a significant challenge. Scaling these models to serve billions of users with multiple daily interactions can quickly accumulate expenses, especially in complex tasks like code auto-completion, where the model remains active throughout the coding process. To address this issue, researchers have delved into enhancing the efficiency of the decoding process, focusing on the crucial element of attention.
Decoding Process Optimization
Generating a single response with LLMs comes at an average cost of $0.01. Yet, when these models cater to extensive user bases with frequent interactions, expenses escalate rapidly. This is particularly true for tasks like code auto-completion, where the model must maintain continuous engagement. Researchers have recognized the need to streamline and expedite attention operations during decoding to curb operational costs.
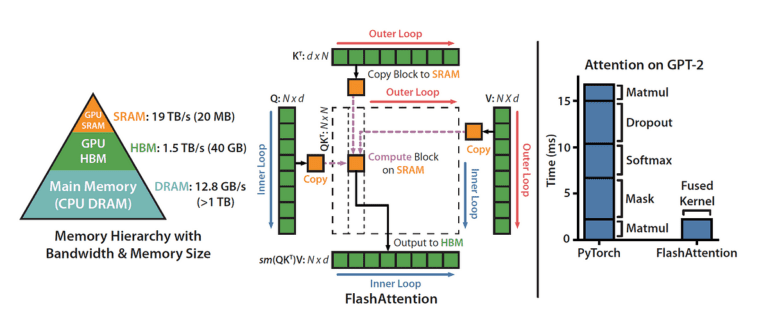
Introducing FlashAttention v2
The incremental generation of tokens during LLM inference, commonly known as decoding, heavily relies on attention actions. While innovations like FlashAttention v2 and FasterTransformer have made significant strides in optimizing memory bandwidth and processing resources during training, challenges persist during the inference phase. Scaling attention operations for extended contexts remains a significant bottleneck in decoding efficiency.
Revolutionary Flash-Decoding
To combat these challenges, researchers have introduced an innovative solution known as Flash-Decoding. Building upon earlier approaches, Flash-Decoding stands out for its unique strategy of parallelization, particularly with regard to sequences of keys and values. This approach harnesses the power of the GPU by partitioning keys and values into smaller fragments, leading to exceptional efficiency even with smaller batch sizes and extended contexts.
Flash-decoding employs parallelized attention computations and the log-sum-exp function to reduce GPU RAM usage and optimize model architecture computation.
Proven Efficacy
Benchmark experiments have been conducted to assess the impact of Flash-Decoding on the CodeLLaMa-34b model, renowned for its robust design and advanced capabilities. The results have been nothing short of remarkable, showcasing an impressive 8-fold increase in decoding speeds for longer sequences compared to conventional methods. Micro-benchmarks, featuring various sequence lengths and batch sizes, consistently reinforce the exceptional performance of Flash-Decoding, even when the sequence length is pushed to 64k. This breakthrough has significantly enhanced the efficiency and scalability of LLMs, marking substantial progress in large language model inference technology.
Conclusion:
The introduction of FlashAttention and Flash-Decoding marks a pivotal shift in the market for large language models. Businesses can now harness the power of LLMs more efficiently, reducing operational costs and accelerating their adoption in diverse applications. This innovation is poised to drive progress in natural language processing technologies, offering companies a competitive edge in delivering enhanced language-based services.